Hadoop

บริษัท Fusion Solution บริการรับติดตั้ง และพัฒนา design Hadoop สำหรับ Big Data มาตราฐานของ Microsoft Gold Partner และ CMMi 3 ให้กับธุรกิจที่ต้องวิเคราะห์ข้อมูลสมัยใหม่โดยทำการรวบรวมข้อมูลทั้งจากภายใน เช่น ระบบบัญชี ระบบบุคคลระบบขาย และข้อมูลภายนอก เช่น ข้อมูล Reference เทียบธุรกิจ หรือ ข้อมูลพฤติกรรมของ User
ด้วยประสบการณ์ของบริษัทกว่า 15 ด้านระบบฐานข้อมูลและมาตรฐานการพัฒนา CMMi
เครื่องมือนี้ คือ หนึ่งในเครื่องมือที่ใช้ในการรวบรวมข้อมูลตัวหนึ่งที่นิยมใช้ในโครงการ Big Data เนื่องจากโครงสร้างเหล่านี้ถูกออกแบบมาเฉพาะสำหรับการรวบรวมข้อมูลที่ไม่ได้เป็น Structure ซึ่งถือว่าเป็นข้อมูลส่วนสำคัญส่วนหนึ่งของ Big Data แต่ทั้งนี้การทำ Big Data แล้ว เครื่องมือนี้เป็นแค่ส่วนหนึ่ง ไม่ได้ถือว่าเป็นทั้งหมดของโครงการนะครับ
Service by Fusion Solution
- ติดตั้งและ Config Power BI Reporting Server
- ออกแบบ Design Power BI Dash Board
- ออกแบบ Design SQL Cube
- ออกแบบ Data Warehouse
- ออกแบบ Infra for Hadoop
- Training Power BI
- ออกแบบ ETL Process
Hadoop คือ
ถ้าพูดถึง Big data เครื่องมือที่จะถูกพูดถึงเป็นอันดับต้นๆ ในตอนนี้คงไม่พ้นเครื่องมือยอดนิยมนี้ ดังนั้นเราจะมาทำความเข้าใจเจ้า มันคืออะไร ทำอะไรได้บ้าง และมีความสำคัญในการพัฒนาระบบ Big data ยังไง
คือ ซอฟท์แวร์ประเภท Open source ที่จัดทำขึ้นเพื่อเป็นแพลตฟอร์มในการจัดเก็บข้อมูล ซึ่งมีกรอบการทำงานเพื่อใช้ในการจัดเก็บข้อมูลและประมวลผลข้อมูลที่มีขนาดใหญ่มากๆ ที่เราเรียกกันว่า Big Data ซึ่งเจ้าตัวเครื่องมือนี้เองเนี่ยก็สามารถปรับขยาย ยืดหยุ่น เพื่อรองรับข้อมูลที่มีจำนวนมากมายมหาศาลได้ ทั้งนี้ก็เพราะมันมีการกระบวนการประมวลผลที่แข็งแกร่งมากซึ่งเป็นผลมาจากการประมวลผลข้อมูลแบบกระจายผ่านเครื่องคอมพิวเตอร์ที่ถูกจัดอยู่ในรูปแบบ Cluster อันนำไปสู่ความสามารถในการรองรับข้อมูลที่ไม่จำกัดแถมยังมีความน่าเชื่อถือสูงอีกด้วย
Hadoop ไม่เหมาะกับอะไร
- ข้อมูลขนาดเล็ก ๆ
- การใช้ข้อมูลที่ต้องการ Real Time เนื่องจาก การทำงานจะเป็นแบบ batch processing
- เก็บข้อมูลที่เป็น Structure เพราะมีตัวเลือกอื่นที่น่าสนใจกว่า เช่น SQL
Hadoop เหมาะสำหรับ
- ตัวอย่างที่ทางบริษัท จำเป็นต้องนำเครื่องมือนี้มาใช้งาน การจัดเก็บข้อมูลจาก Web เนื่องจากการวิเคราะห์ข้อมูล ณ. ปัจจุบัน บริษัทต้องการนำข้อมูลภายนอกมาเป็น ตัวแปลในการพิจารณา และ เนื่องจากข้อมูลภายนอกเป็นข้อมูลที่ไม่มีโครงสร้าง และ มีอัตราการขยายตัวที่เร็วมาก ดังนั้น เครื่องมือนี้จึงเป็นตัวเลือกที่ดีสำหรับ กรณีนี้
Hadoop Spec Server
- การใช้งานเครื่องมือนี้บน Server นั้น เราต้องมีการจัดเตรียม Spec ให้เหมาะสมกับลักษณะ การทำงานด้วย โดยเฉพาะ ของ การใช้งานเครื่องมือนี้เองที่มีการทำงานอยู่ใน Harddisk เป็นหลัก ( เนื่องจากมันเกิดมาในสมัยที่ RAM ยังมีขนาดนิดเดียว ) ดังนั้น Spec ของ Server จึงควรพิจารณา HD ที่มีความเร็วในการเขียน อ่าน และ มีความจุที่มาก ส่วนของ RAM หรือ CPU นั้น ไม่ซีเรียส ครับ
ตัวอย่าง Infrastructure ของ Big Data
เพื่อให้เห็นภาพที่ชัดเจนขึ้นสำหรับโครงการ Big Data ที่ใช้เครื่องมือนี้ เป็น Application หลักในการ Implement เลยขอยกตัวอย่าง Spec งาน Infrastructure ที่เขียนไว้ ยกมาให้เป็นตัวอย่างกันนะครับ เริ่มจาก ชุด Server ดังนี้ครับ
- Management Node Server จำนวน 1 ชุด
- OS : Linux
- Resource Manager Server (Name Node) จำนวน 2 ชุด
- OS : Linux
- Hadoop Apache
- Worker Nodes Server จำนวน 3 ชุด
- OS : Linux
- Hadoop Apache
- Report Node Server จำนวน 1 ชุด
- OS : Linux
- xxxx ( Up to you )
- Edge Node Server จำนวน 1 ชุด
- OS : Linux
โครงสร้างของ Hadoop
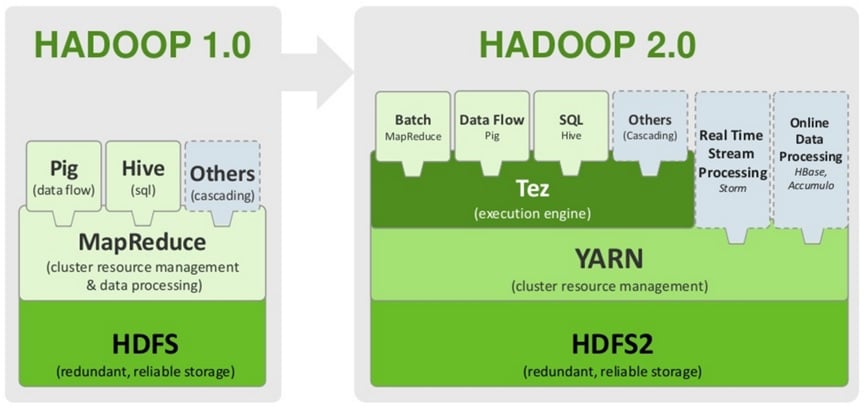
ทำความเข้าใจโครงสร้างของเครื่องมือนี้กันอีกซักนิดหน่อยนะครับ เราจะได้รู้ว่า มันทำงานได้ยังไง แล้ว ถ้ามีปัญหาเราจะแก้ไขได้ยังไง ลองมาดูกันเลยว่า มีประกอบด้วยอะไรบ้าง
- จากภาพจะเป็นพัฒนาการของ จากเวอร์ชั่น 1.x จนปัจจุบัน เป็น เวอร์ชั่น 2.x (2.7.2) ซึ่งประกอบไปด้วยส่วนต่างๆ และการทำงานไล่จากล่างขึ้นบนดังนี้
- HDFS (Hadoop Distributed File System) : คือระบบจัดการไฟล์ แบบพิเศษของเครื่องมือนี้
- YARN : เป็นตัวที่เพิ่มเข้ามาใน เวอร์ชั่น 2.0 ซึ่งจะเป็นพระเอกมาคอยช่วยในการจัดการ cluster ของเราเวลาที่จ่ายงาน (Job กับ Task) และการติดตามงานของ MapReduce
- MapReduce: คือ Distributed Programming Framework
- Pig : เป็นภาษาสคริปต์ที่เหมาะกับงาน Pipeline processing
- Hive: ถ้าจะมองว่าเป็น Distribute Database Management System ก็ได้เพราะถ้าพวก RDBMS (row-oriented) ทั่วๆไป จะไม่รองรับการเก็บข้อมูลแบบกระจายไปอยู่ในหลายๆที่ แจะการจัดการกับข้อมูลขนาดใหญ่ ส่วนใหญ่ถ้าเราอยากให้การสรุปข้อมูลได้ง่ายขึ้น ก็จะมีการ load ไฟล์จาก HDFS มาเข้า Hive ก่อนแล้วค่อยเขียน Query เหมือนกับการใช้ SQL ทั่วๆไป ซึ่งโดยรวมจะเร็วกว่าการทำ MapReduce หรือเขียน Pig
- HBase: ใช้วิธีเก็บข้อมูลแบบ column-oriented นั่นคือเราสามารถเพิ่ม column ได้ไม่จำกัดเพียงแต่ต้องกำหนด column-family ให้เรียบร้อยก่อนแค่นั้น เพื่อแก้ปัญหาการเก็บข้อมูลของ Hive ที่เป็นเหมือน RDBMS ทั่วไปที่จะต้องมี Schema (โครงสร้างตาราง) ที่ชัดเจนก่อน เวลาจะเพิ่ม column จะต้องมานั่ง alter table ดังนั้น HBase จึงเหมาะสำหรับข้อมูลที่มี Schema ไม่แน่นอน และอาจมีการเพิ่ม column ในภายหลังได้โดยที่ไม่กระทบกับโครงสร้างการเก็ฐข้อมูล อารมณ์คล้ายพวก NoSQL หรือ MongoDB นั่นเองแต่สามารถทำงานแบบกระจายตัวได้บนพื้นฐานของ HDFS
สามารถสอบถามข้อมูลเพิ่มเติมได้ที่ https://www.facebook.com/fusion.solution
บทความที่เกี่ยวข้อง

