บทที่ 16-Two-Class Logistic Regression
วิธีการ Classification การอนุมัติเงินกู้ด้วยโมเดล Two-Class Logistic Regression โดยใช้ AzureML
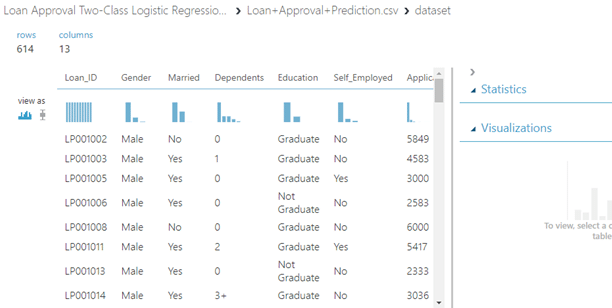
ในบทความนี้เราจะมาทำการ Classification โดยใช้โมเดลที่มีชื่อว่า Two-Class Logistic Regression ที่เราสามารถสร้างได้ง่าย ๆโดยใช้เครื่องมือที่มีชื่อว่า AzureML ค่ะ ซึ่งข้อมูลที่เราต้องการ Classify ในบทความนี้คือข้อมูลการอนุมัติเงินกู้ซึ่งมีจำนวน 614 แถว 13 คอลัมน์ โดยมี Target หรือเป้าหมายของการ Classification ของเราคือคอลัมน์ที่มีชื่อว่า Loan_Status โดยที่ Y แทนสถานะอนุมัติ และ N แทนสถานะไม่อนุมัติ
ซึ่งมีวิธีการในการ Classification โดยใช้ AzureML ดังนี้
- นำข้อมูลจากเครื่องเข้ามาที่ AzureML โดยกด NEW ตามด้วย DATASET คลิก From local File เพื่อเลือกข้อมูลที่อยู่ในเครื่องของเราเข้ามา จากนั้นเลือกนามสกุลไฟล์ และเลือกว่าไฟล์ที่เรานำเข้ามาต้องการให้มี header หรือชื่อคอลัมน์ไหมตามที่เราต้องการ และกดตรงเครื่องหมายถูก
- ลากข้อมูลที่เราต้องการ Clean หรือต้องการสร้างโมเดลมาไว้บน Workspace โดยนำข้อมูลที่เรานำเข้ามาจาก Saved Dataset เลือก My Datasets จากนั้นลากชุดข้อมูลที่เราต้องการมาไว้บน Workspace
- จากนั้นเราจะดูรายละเอียดของชนิดของข้อมูลโดยการคลิกขวาที่วงกลมเล็ก ๆ ใต้ชุดข้อมูลที่เรานำมาวาง แล้วเลือก Visualize เพื่อดูรายละเอียดของข้อมูล พบว่า
- มี missing value เกือบทุกคอลัมน์ทั้งคอลัมนที่เป็น String และคอลัมน์ที่เป็น numeric
- มีคอลัมน์ที่ไม่มีผลต่อ Classification คือ Loan_ID
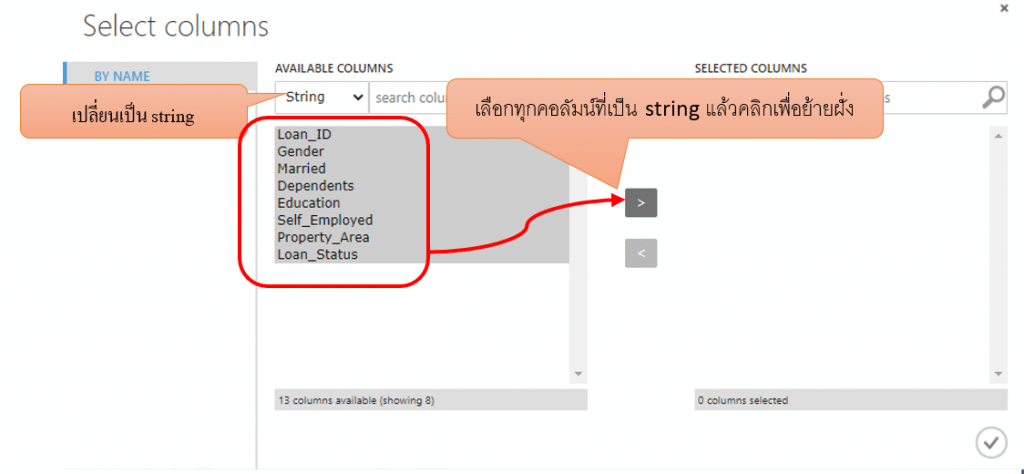
- Clean missing data ของคอลัมน์ที่มีชนิดข้อมูลเป็น string โดยการค้นหา module ที่มีชื่อว่า Clean Missing Data แล้วลากมาวางบน Workspace จากนั้นลากเส้นเชื่อมกับชุดข้อมูลของเรา จากนั้นคลิก Launch column selector จากนั้นกดเลือกคอลัมน์โดยเลือกข้อมูลที่เป็น string ทั้งหมดที่เราต้องการมาไว้ทาง Selected Columns แล้วคลิกเครื่องหมายถูก
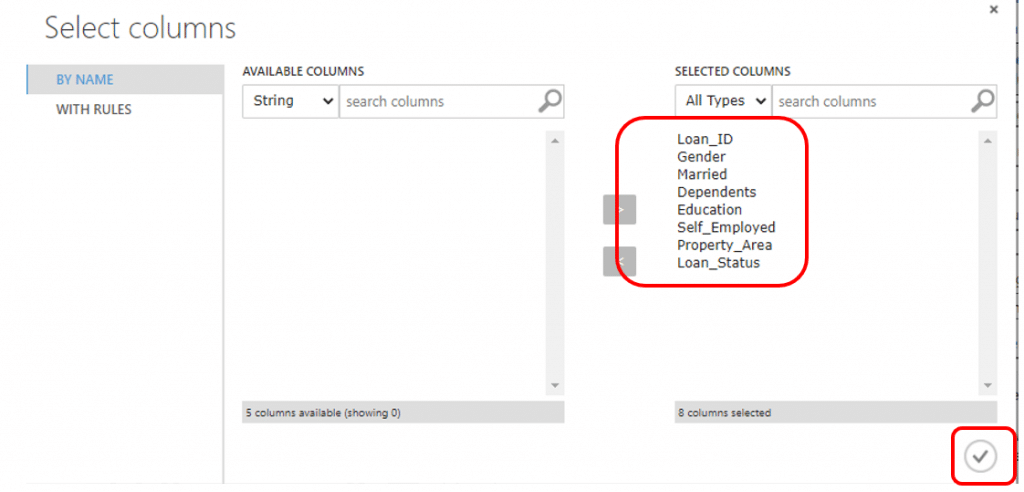
จากนั้นเลือก parameter เป็น Replace with mode แล้กคลิก RUN
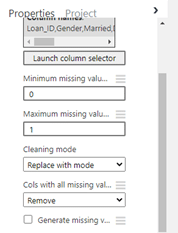
ในทำนองเดียวกันเราจะ clean คอลัมน์ที่เป็น numeric ทุกคอลัมน์ด้วย Replace with mean
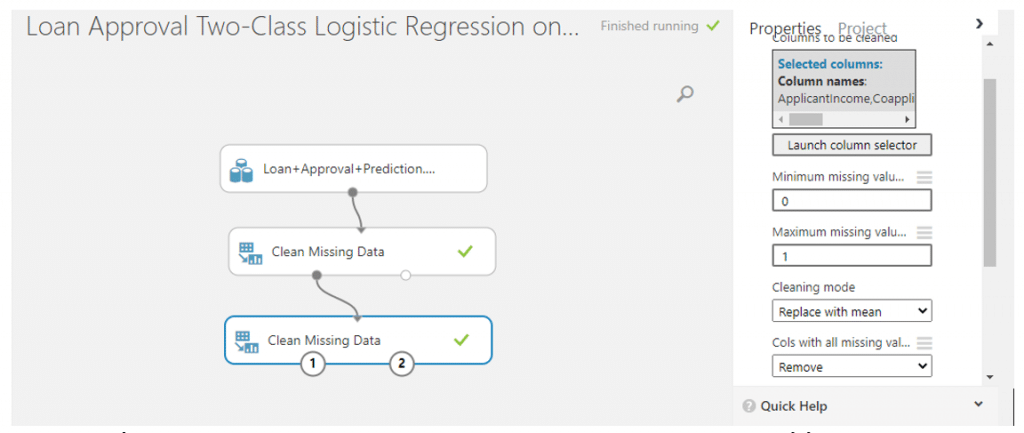
เลือกคอลัมน์ที่นำมาใช้ในการวิเคราะยกเว้น Loan_ID โดยการค้นหา module ที่ชื่อว่า Select columns in dataset แล้วคลิก Launch column selector โดยเลือกทุกแถวยกเว้น Loan_ID แล้วคลิก RUN
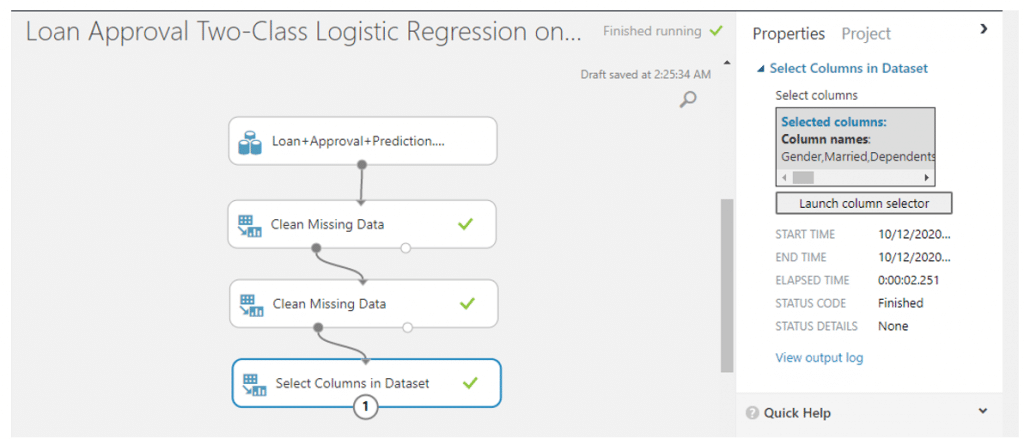
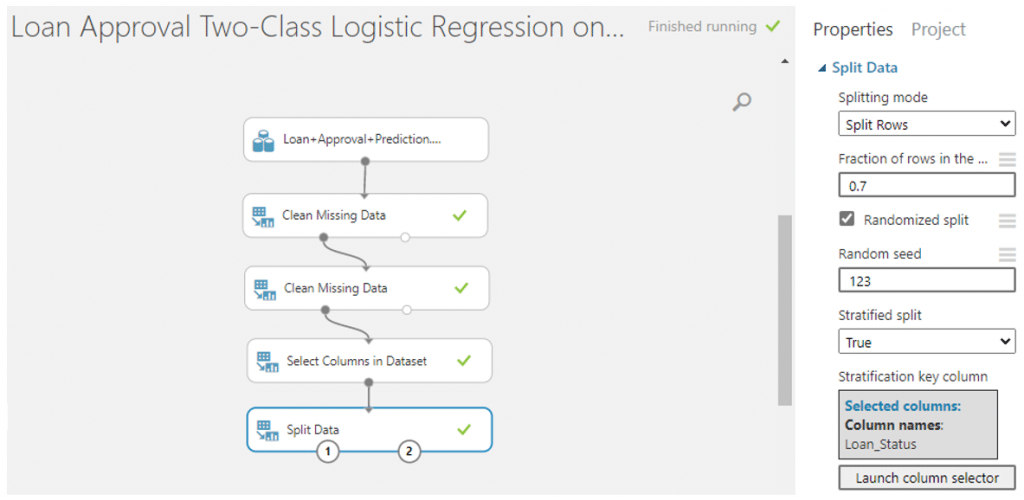
- จากนั้นเราจะแยกข้อมูลออกเป็น training set เพื่อใช้ในการ train ข้อมูลและ test set เพื่อทดสอบข้อมูลสามารถทำได้โดยการค้นหา module ที่มีชื่อว่า Split Data จากนั้นทำการปรับค่า parameter ดังนี้
- Splitting mode เลือก Split Rows
- Fraction of rows in the first output dataset ใส่ค่า 0.7 นั้นคือเราจะแบ่งเป็น training set 70% และ test set 30% แล้วใส่เครื่องหมายถูกตรง Randomized split
- Random Seed เราสามารถใส่เลขอะไรก็ได้เพื่อให้การสุ่มในทุก ๆ ครั้งได้เลขเดิมโดยในที่นี่เราจะใส่ 123
- Stratified split เลือก true จากนั้นเลือกคอลัมน์ที่เป็น target ของเรานั้นคือ Loan_Status
เมื่อตั้งค่าทุก parameter เสร็จแล้วคลิก RUN
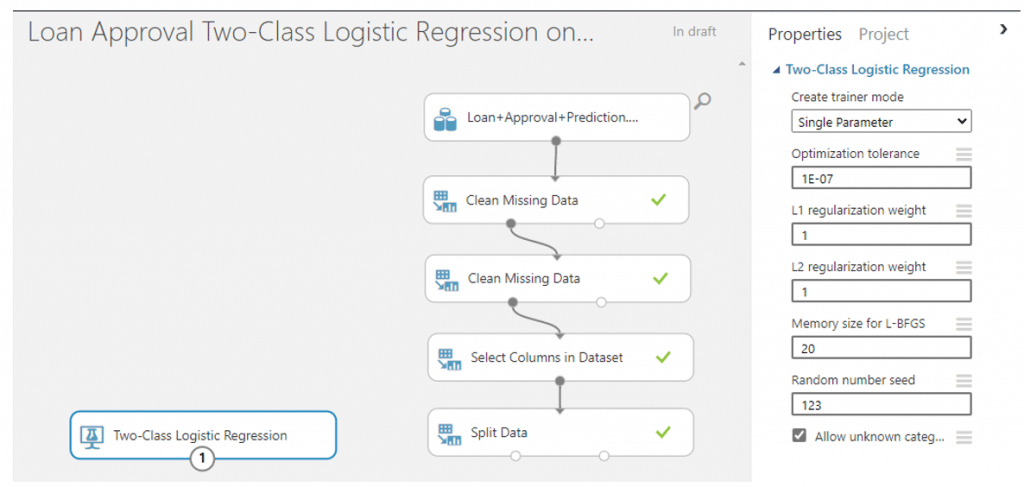
- ค้นหา module ที่มีชื่อว่า Two-Class Logistic Regression เพื่อทำการสร้างและ train โมเดล โดยค่า parameter แต่ละค่ามีความหมายดังนี้
- Create trainer mode
- Single Parameter : ระบุ set ของค่าเฉพาะ
- Parameter Range : ระบุค่าเฉพาะหลายค่าและรับ set ที่เหมาะสมที่สุดสำหรับกำหนดค่า
- Optimization tolerance : ค่าเกณฑ์ที่ใช้เพื่อหยุดการทำซ้ำแบบจำลองบน training set
- L1 regularization weight : ลดค่าสัมประสิทธิ์ทั้งหมดตามสัดส่วนเดียวกันแต่ไม่กำจัดเลย
- L2 regularization weight : สามารถลดค่าสัมประสิทธิ์บางส่วนให้เป็นศูนย์โดยทำการเลือกตัวแปร ทั้ง L1 และ L2 เราต้องทำให้เป็นมาตรฐานเพื่อป้องกันไม่ให้เกิดการ Overfitting โดยการลดขนาดสัมประสิทธิ์ โดย L2 มันจะมีน้ำหนักน้อย ส่วน L1 มักจะมีน้ำหนักที่มากกว่า และทั้งสองจะมีค่ามากกว่าศูนย์
- Memory size for L-BFGS : จำนวนหน่วยความจำที่ใช้สำหรับทิศทางและขั้นตอนถัดไป
- Random number seed : เราสามารถใส่เลขอะไรก็ได้เพื่อให้การสุ่มในทุก ๆ ครั้งได้เลขเดิมโดยในที่นี่เราจะใส่ 123
- Allow unknown categorical levels : สร้างระดับ unknow เพิ่มเติม
- Create trainer mode
โดยในข้อมูลนี้เราจะกำหนดค่าเหล่านี้ตาม AzureML กำหนดมาแล้ว
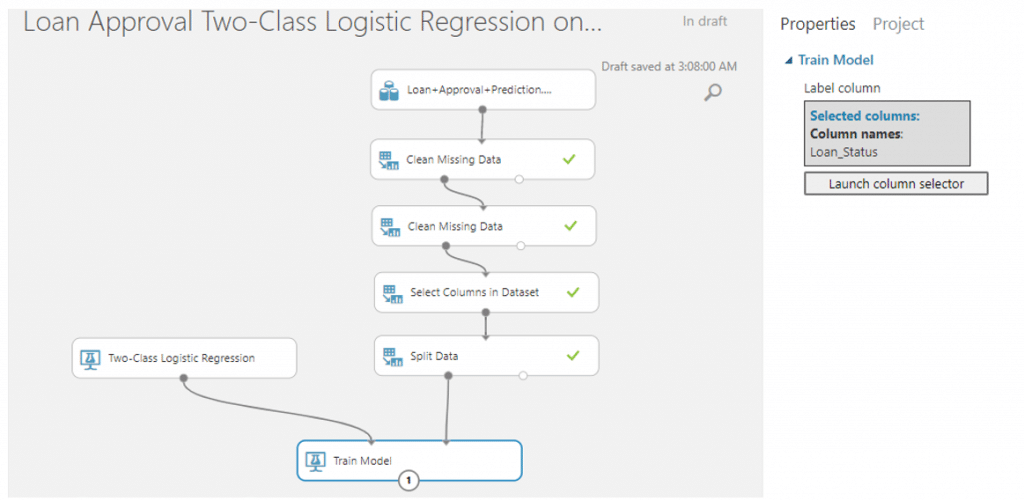
จากนั้นค้นหา module ที่ชื่อว่า Train Model ลากมาวางบน Workspace และลากเส้นเชื่อมจาก Two-Class Logistic Regression มาเชื่อมกับวงกลมวงแรกและลากจากวงกลมวงแรกอง Split Data มาเชื่อมวงกลมวงที่สองของ Train Model จากนั้นเลือกคอลัมน์ Loan_Status
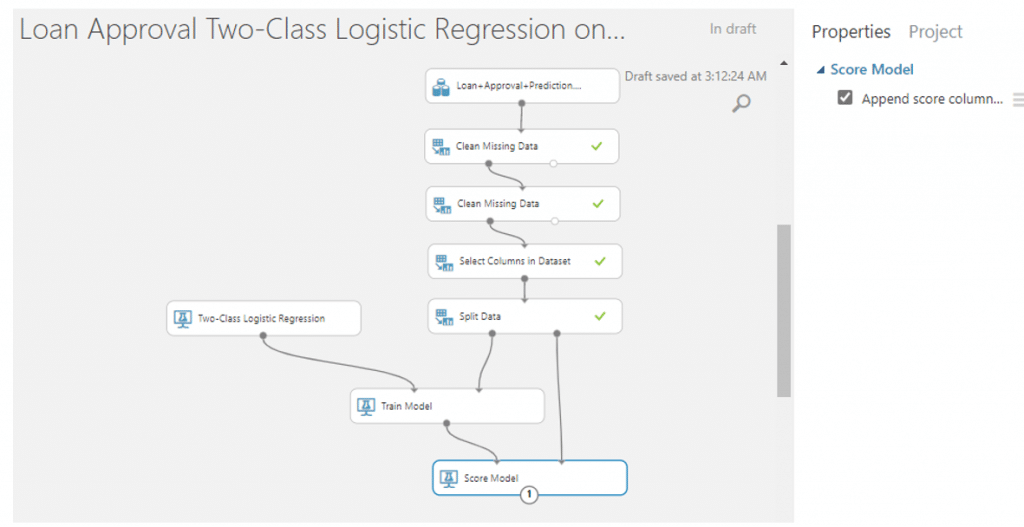
จากนั้นค้นหา module ที่ชื่อว่า Score Model มาวางบน Workspace แล้วลากเส้นเชื่อมจาก Train Model มาเชื่อมที่วงกลมวงแรก และลากจากวงกลมที่สองของ Split Data มาเชื่อมกับวงที่สองของ Score Model
จากนั้นค้นหา module ที่ชื่อว่า Evaluate Model มาวางบน Workspace แล้วลากเส้นเชื่อมจาก Score Model มาที่ Evaluate Model เพื่อดูประสิทธิภาพของโมเดลของเรา จากนั้นกด RUN
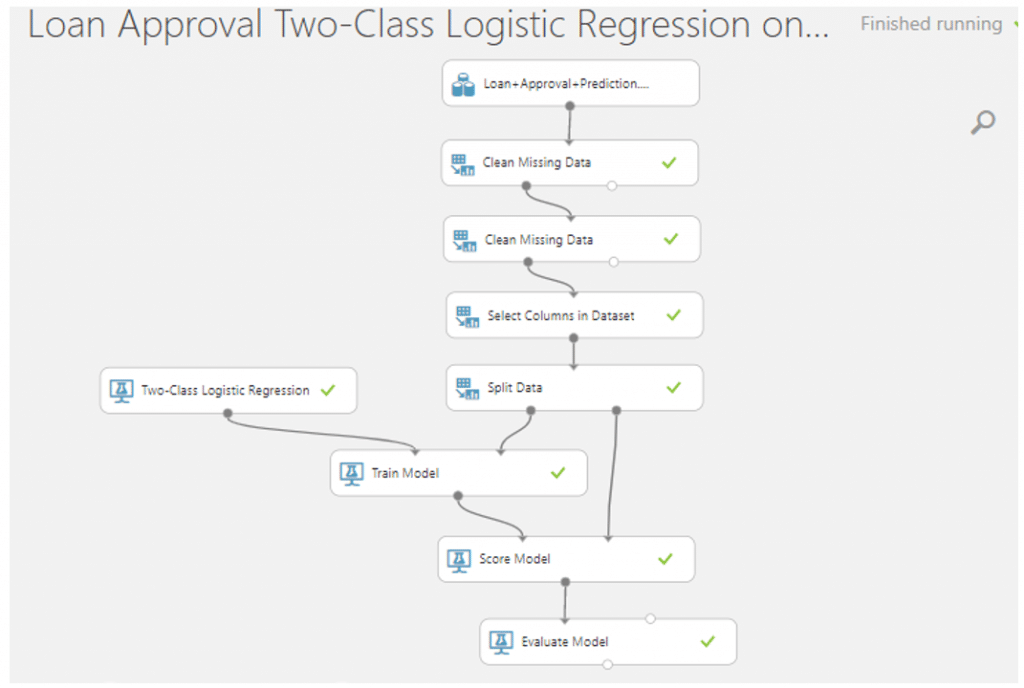
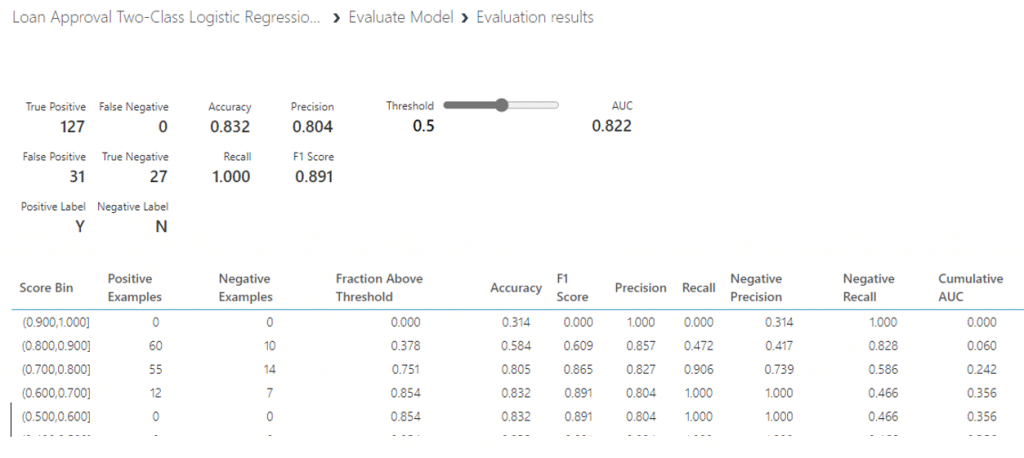
Visualize ดูประสิทธิภาพของโมเดลจะพบว่า โมเดลของเราสามารถ Classification ได้ค่าความถูกต้อง 0.832 หรือเท่ากับ 83.2 % และค่าที่ใช้วัดประสิทธิภาพของโมเดลมีค่าที่สูงทุก ๆ ค่า ทำให้เราสามารถสรุปได้ว่า Two-Class Logistic Regression เป็นโมเดลที่มีประสิทธิภาพที่ดีและเหมาะในการ Classification ข้อมูลการอนุมัติเงินกู้
Fusion ให้บริการวิเคราห์และออกแบบระบบ Machine Learning ด้วยเครื่องมือ ของ
Microsoft Azure
02-440-0408 / sales@fusionsol.com
Link to Implement Azure , Implement Power BI