บทที่ 19-Two-Class Decision Forest
วิธีการ Classification รายได้ด้วยโมเดล Two-Class Decision Forest โดย AzureML
วิธีการ Classification ข้อมูลนั้นมีหลากหลายวิธีการให้เราได้เลือกมาใช้ในการแยกข้อมูลของเราและหนึ่งในวิธีการที่นิยมถูกนำมาใช้ในการ Classification คือ Random Forest หรือ Decision Forest โมเดลที่เกิดจากการนำ Decision tree หลาย ๆ ต้นในการ Classify ข้อมูลของเราจากนั้นจะทำการโหวตผลลัพธ์ที่ได้มากที่สุดจากต้นไม้ทุกต้น
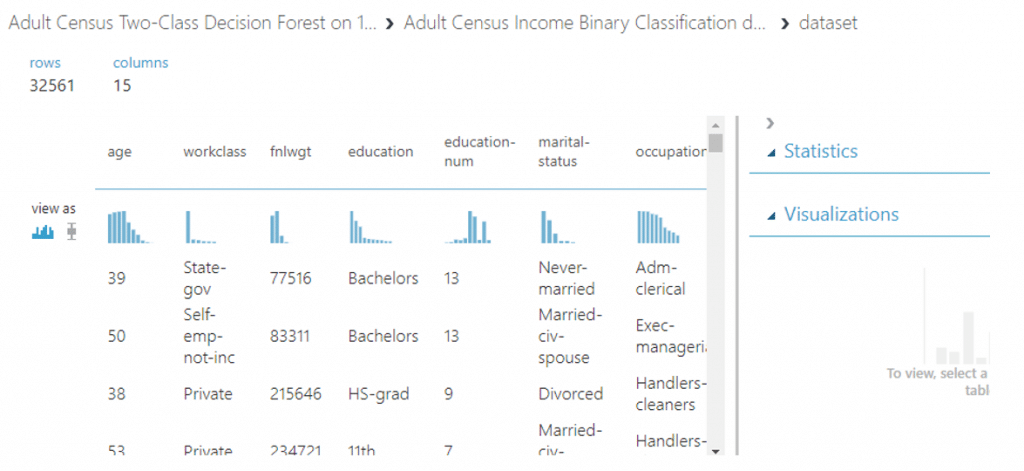
ข้อมูลที่เราต้องการจะทำการ Classify วันนี้คือชุดข้อมูลที่ชื่อว่า Adult Census Income ที่มี 32561 แถว และ 15 คอลัมน์โดยมีเป้าหมายคือต้องการแยกประเภทของรายได้ของประชากร โดยการแยกเป็น 2 ประเภทคือ ผู้ที่มีรายได้น้อยกว่าหรือเท่ากับ 50000 และผู้ที่มีรายได้มากกว่า 50000 บาท โดยข้อมูลของเรามี feature ที่ช่วยในการทำ Classification ทั้งหมด 14 feature และมี target หรือคอลัมน์ที่เราต้องการทำ Classification คือ Income โดยเราสามารถทำ Classification ได้ง่ายโดยใช้ AzureML ได้ดังนี้
ค้นหาข้อมูล Adult Census Income จาก Sample Dataset แล้วลากมาวางบน Workspace จากนั้น Visualize เพื่อดูรายละเอียดของข้อมูลพบว่า
- มี missing data ในคอลัมน์ Workclass, Occupation, Native Country
- มีคอลัมน์ที่เกี่ยวข้องกับการทำ Classification รายได้ในครั้งนี้คือ Fnlwgt และ Education-Num
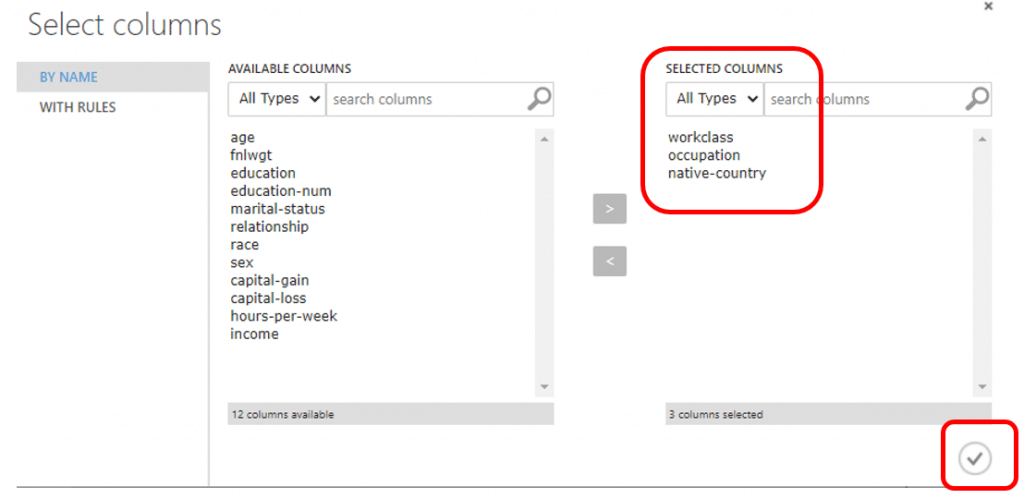
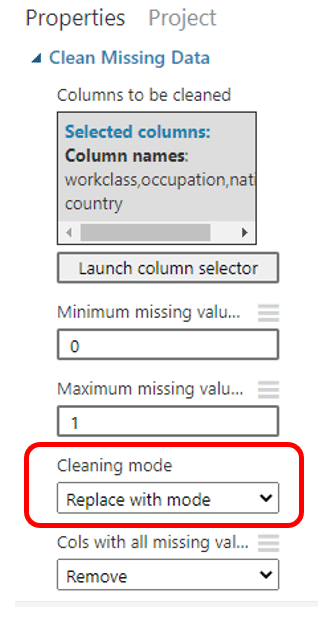
เนื่องจากทุกคอลัมน์ที่มี missing data มีชนิดข้อมูลเป็น string เราจะทำการ Clean missing Data โดย ค้นหา module ที่มีชื่อว่า Clean Missing Data แล้วลากมาวางบน Workspace จากนั้นลากเส้นเชื่อมกับชุดข้อมูลของเรา จากนั้นคลิก Launch column selector จากนั้นกดเลือกคอลัมน์ Workclass, Occupation, Native Country มาไว้ทาง Selected Columns แล้วคลิกเครื่องหมายถูก
จากนั้นเลือก parameter เป็น Replace with mode แล้กคลิก RUN
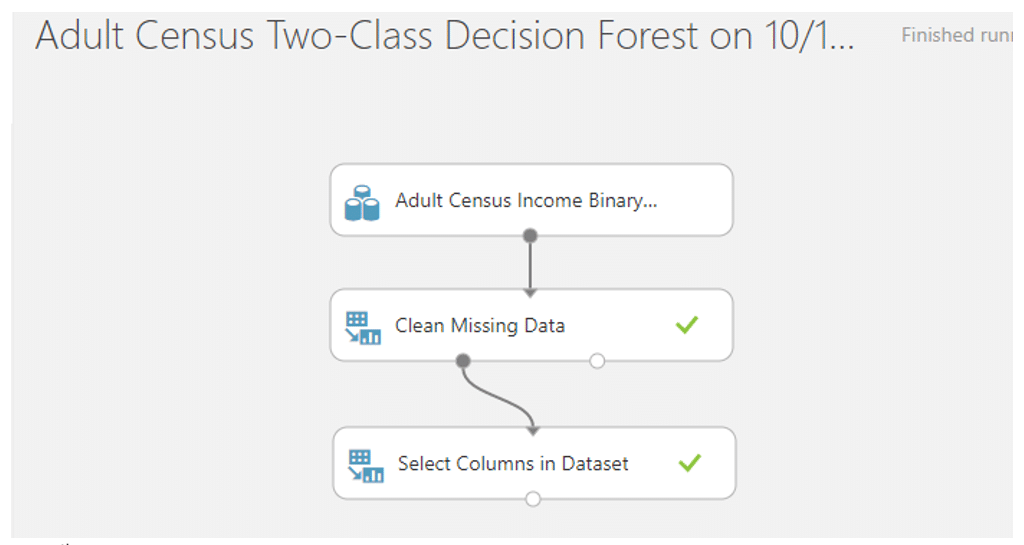
เลือกคอลัมน์ที่นำมาใช้ในการวิเคราะยกเว้น Fnlwgt และ Education-Num โดยการค้นหา module ที่ชื่อว่า Select columns in dataset แล้วคลิก Launch column selector โดยเลือกทุกแถวยกเว้น Fnlwgt และ Education-Num แล้วคลิก RUN
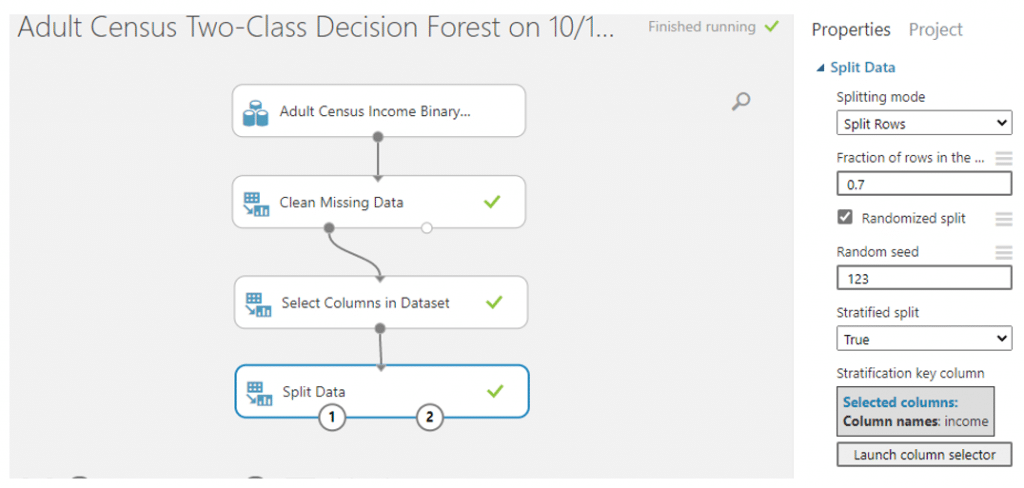
จากนั้นเราจะแยกข้อมูลออกเป็น training set เพื่อใช้ในการ train ข้อมูลและ test set เพื่อทดสอบข้อมูลสามารถทำได้โดยการค้นหา module ที่มีชื่อว่า Split Data จากนั้นทำการปรับค่า parameter ดังนี้
- Splitting mode เลือก Split Rows
- Fraction of rows in the first output dataset ใส่ค่า 0.7 นั้นคือเราจะแบ่งเป็น training set 70% และ test set 30% แล้วใส่เครื่องหมายถูกตรง Randomized split
- Random Seed เราสามารถใส่เลขอะไรก็ได้เพื่อให้การสุ่มในทุก ๆ ครั้งได้เลขเดิมโดยในที่นี่เราจะใส่ 123
- Stratified split เลือก true จากนั้นเลือกคอลัมน์ที่เป็น target ของเรานั้นคือ income
เมื่อตั้งค่าทุก parameter เสร็จแล้วคลิก RUN
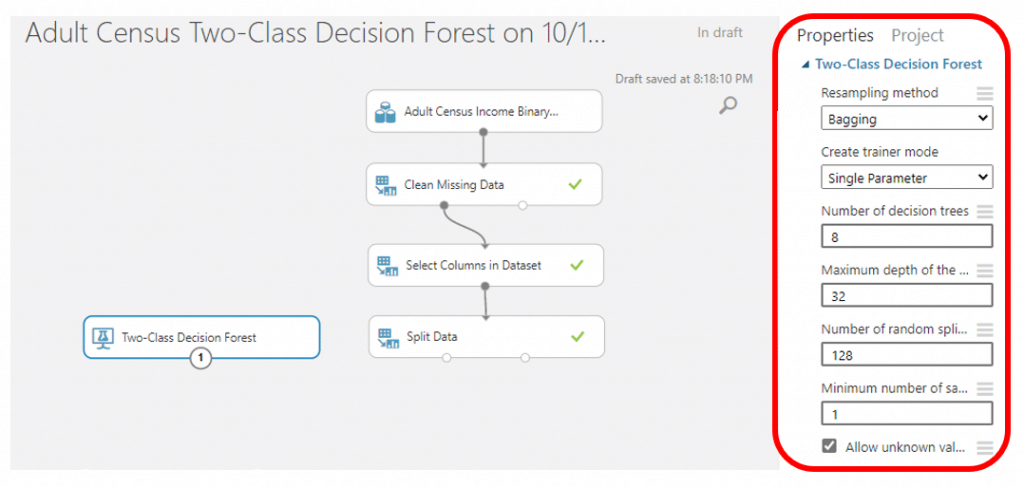
ค้นหา module ที่มีชื่อว่า Two-Class Decision Forest เพื่อทำการสร้างและ train โมเดลโดยค่า parameter แต่ละค่ามีความหมายดังนี้
- Resampling method
- Replicate : แต่ละ tree จะถูก train ด้วย dataset ชุดเดียวกัน
- Bagging : decision trees แต่ละต้นจะสร้างจากตัวอย่างใหม่ โดยจะทำการสุ่มตัวอย่างของ dataset แบบ with replacement และผลลัพธ์ที่ได้จากการโหวตจาก tree ทุกต้น
- Create trainer mode :
- Single Parameter : ระบุ set ของค่าเฉพาะ
- Parameter Range : ระบุค่าเฉพาะหลายค่าและรับ set ที่เหมาะสมที่สุดสำหรับกำหนดค่า
- Number of decision trees : จำนวนของ decision trees ที่เราต้องการใช้ในทำ Classification
- Maximum depth of the decision trees : ความลึกสูงสุดของ decision trees ทุกต้น ซึ่งหากมีความลึกมากอาจเพิ่ม Precision แต่ก็เพิ่มความเสี่ยงในการเกิด overfitting ได้เช่นเดียวกัน
- Number of random splits per node : Number of splits ใช้เมื่อสร้างแต่ละ node ของ tree ซึ่งการ split หมายความว่า feature ในแต่ละระดับของ tree (node) จะถูกแบ่งแบบสุ่ม
- Minimum number of samples per leaf node : จำนวนที่น้อยที่สุดของตัวอย่างต่อ leaf node หรือ จำนวน case ที่เราต้องการ
- Allow unknown for categorical features : สร้างระดับ unknow เพิ่มเติม
- โดยในข้อมูลนี้เราจะกำหนดค่าเหล่านี้ตาม AzureML กำหนดมาแล้วและเลือก Resampling method เป็น Bagging
จากนั้นค้นหา module ที่ชื่อว่า Train Model ลากมาวางที่ canvas และลากเส้นเชื่อมจาก Two-Class Decision Forest มาเชื่อมกับวงกลมวงแรกและลากจากวงกลมวงแรกอง Split Data มาเชื่อมวงกลมวงที่สองของ Train Model จากนั้นเลือกคอลัมน์ income
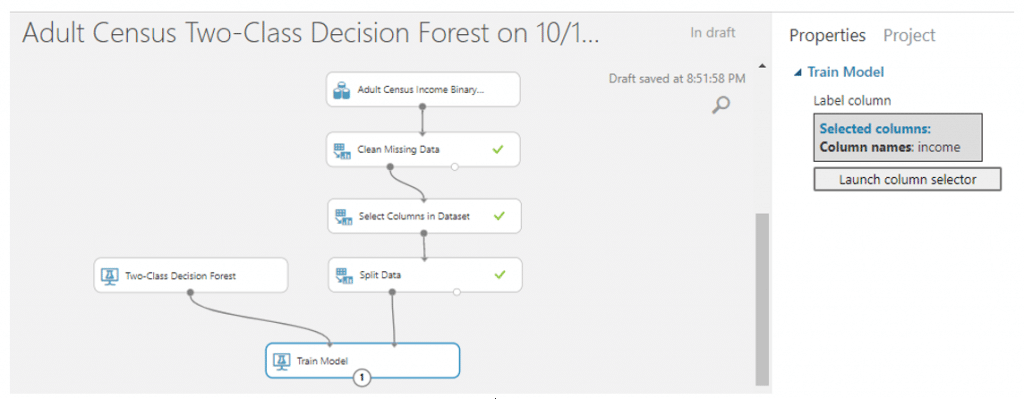
จากนั้นค้นหา module ที่ชื่อว่า Score Model มาวางบน Workspace แล้วลากเส้นเชื่อมจาก Train Model มาเชื่อมที่วงกลมวงแรก และลากจากวงกลมที่สองของ Split Data มาเชื่อมกับวงที่สองของ Score Model
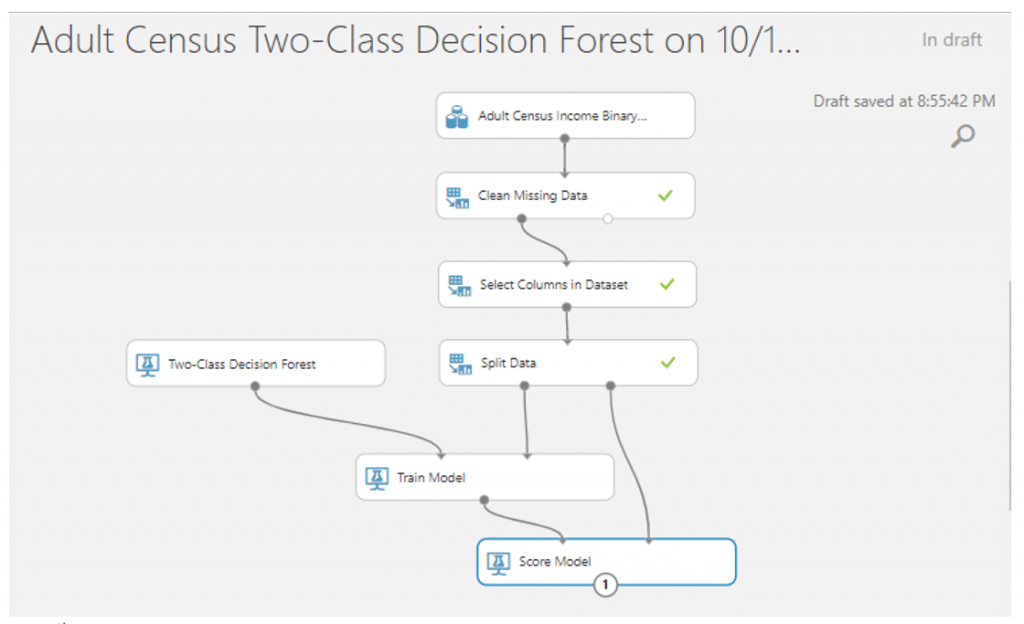
จากนั้นค้นหา module ที่ชื่อว่า Evaluate Model มาวางบน Workspace แล้วลากเส้นเชื่อมจาก Score Model มาที่ Evaluate Model เพื่อดูประสิทธิภาพของโมเดลของเรา จากนั้นกด RUN
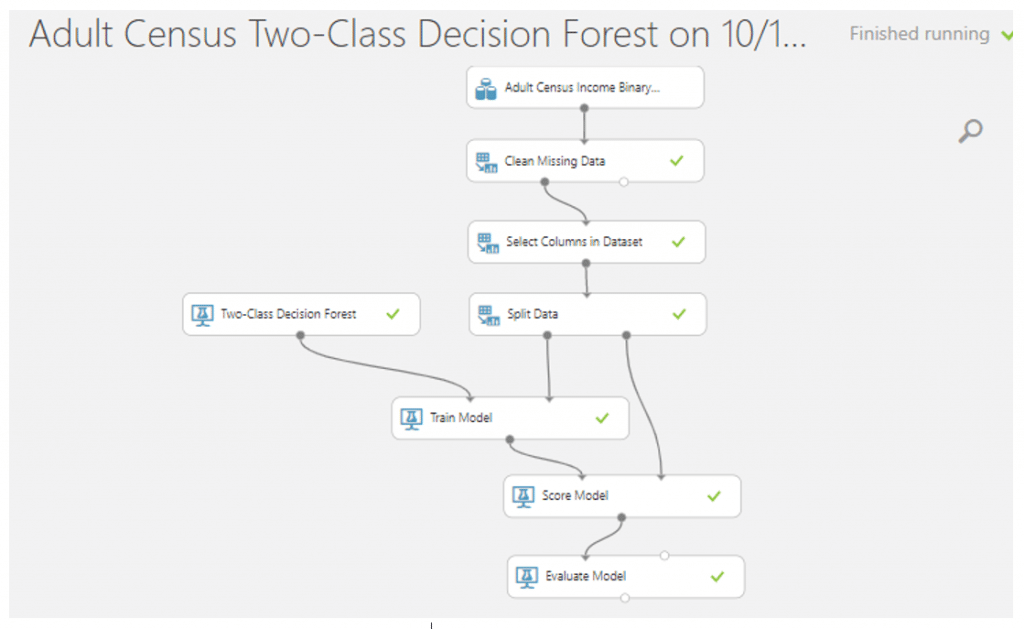
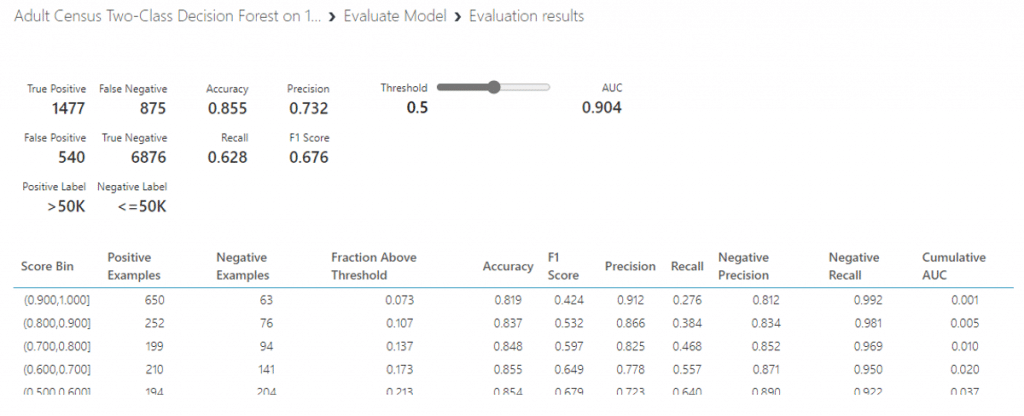
Visualize ดูประสิทธิภาพของโมเดลจะพบว่า โมเดลของเราสามารถ Classification ได้ค่าความถูกต้อง 0.855 หรือเท่ากับ 85.5 % และมีค่า AUC เท่ากับ 0.904 และค่าที่ใช้วัดประสิทธิภาพของโมเดลมีค่าที่สูงทุก ๆ ค่า ทำให้เราสามารถสรุปได้ว่า Two-Class Decision Forest เป็นโมเดลที่มีประสิทธิภาพที่ดีและเหมาะในการ Classification ข้อมูลรายได้ของประชากร
Fusion ให้บริการวิเคราห์และออกแบบระบบ Machine Learning ด้วยเครื่องมือ ของ
Microsoft Azure
02-440-0408 / sales@fusionsol.com
Link to Implement Azure , Implement Power BI