บทที่ 18-Two Class Boosted Decision Tree
Boosted Decision Tree เป็นโมเดลแบบ Supervised Learning method และเป็นโมเดลแบบ Ensamble แบบ Boosting หรือการนำ Weak Classifier (แม่นยำต่ำ) มาทำนายข้อมูลที่เรามีจากนั้นให้ weak ตัวใหม่แก้ไข error เรื่อย ๆ เป็น Decision Tree ต่อกันเป็นลำดับหลาย ๆ ต้น ซึ่งวิธีการนี้จะทำนายความซับซ้อนได้ดีกว่าแบบ Bagging ที่นำผลจาก Decision Tree มาโหวตกัน แต่มีข้อเสียคือใช้เวลานานกว่านั้นเองค่ะ

Dataset ที่เราต้องการจะทำ Classification ในวันนี้คือ Bank Telemarketing หรือการทำการตลาดทางโทรศัพท์ของธนาคาร ซึ่งข้อมูลมีจำนวน 41188 แถว 21 คอลัมน์ และเป้าหมายที่เราต้องการคาดการณ์หรือ Classify คือลูกค้าที่ทางธนาคารโทรไปเสนอขายสินค้าทางโทรศัพท์จะสมัครรับสินค้าหรือไม่ นั้นคือ คอลัมน์ Y โดยที่ Yes คือลูกค้าสมัครรับสินค้า และ No คือลูกค้าไม่สนใจสมัครรับสินค้า โดยมีวิธีการ Classify ดังนี้
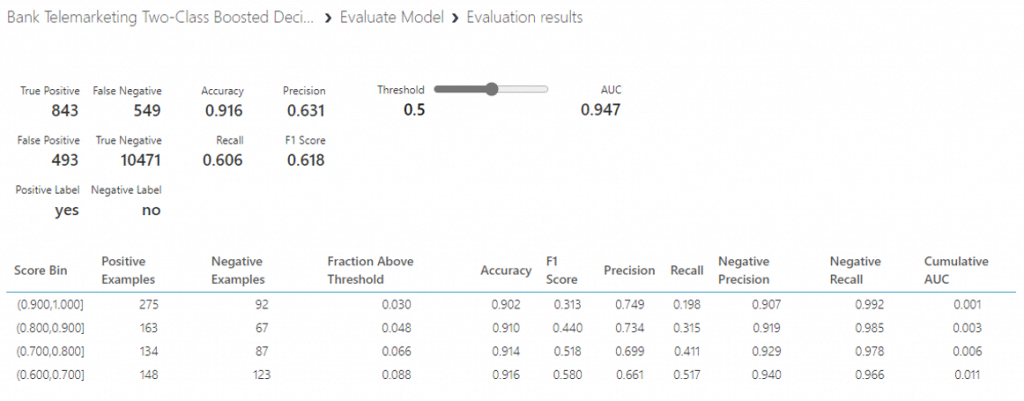
- นำข้อมูลของธนาคารที่เรานำเข้ามาไว้ที่ AzureML แล้วมาวางบน Workspace จากนั้นเราจะ Visualize ดูรายละเอียดต่าง ๆ ของข้อมูลว่าเราต้องทำการ Preprocess ก่อนหรือไม่ ซึ่งเราจะพบว่าข้อมูลของเราไม่ต้องทำ Preprocess แล้วค่ะ
- จากนั้นเราจะแยกข้อมูลออกเป็น training set เพื่อใช้ในการ train ข้อมูลและ test set เพื่อทดสอบข้อมูลสามารถทำได้โดยการค้นหา module ที่มีชื่อว่า Split Data จากนั้นทำการปรับค่า parameter โดยปรับ Fraction of rows in the first output dataset เป็น 0.7 เพื่อแบ่งข้อมูลเป็น training set 70% และ test set 30% และใส่ค่า 123 ใน Random Seed และเลือก Stratified split เลือก true จากนั้นเลือกคอลัมน์ที่เป็น target ของเรานั้นคือ y จากนั้นคลิก RUN
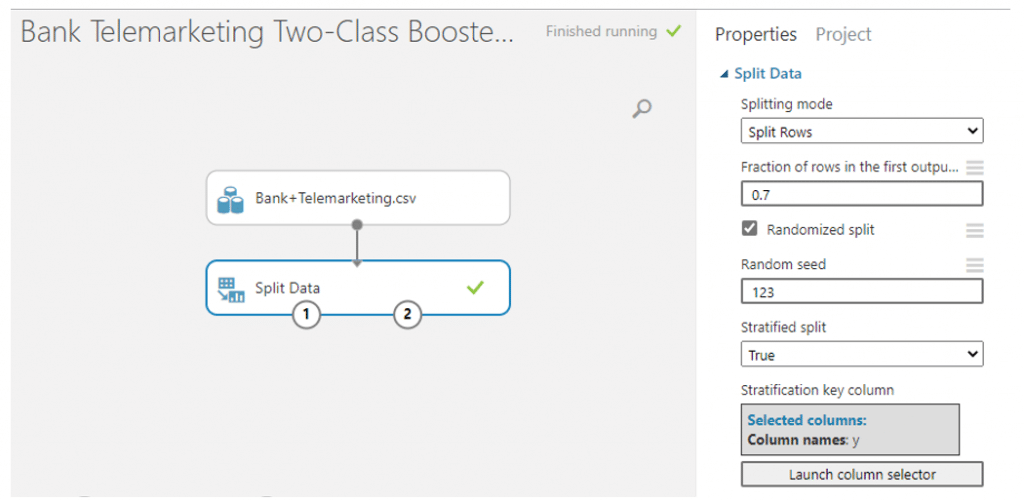
ค้นหา module ที่มีชื่อว่า Two-Class Boosted Decision Tree เพื่อทำการสร้างและ train โมเดล โดยค่า parameter แต่ละค่ามีความหมายดังนี้
- Create trainer mode
- Single Parameter : ระบุ set ของค่าเฉพาะ
- Parameter Range : ระบุค่าเฉพาะหลายค่าและรับ set ที่เหมาะสมที่สุดสำหรับกำหนดค่า
- Maximum number of leaves per tree : ค่านี้สามารถเพิ่มขนาดของ Tree และสามารถเพิ่มผล Precision และแต่หากเราใส่ค่ามากไปอาจทำให้เกิดความเสี่ยงในการ Overfitting และมีเวลาในการ Train นาน
- Minimum number of samples per leaf node : จำนวนที่น้อยที่สุดของตัวอย่างต่อ leaf node หรือจำนวน case ที่เราต้องการ หรือการเพิ่ม ลด ขีดจำกัดสำหรับการสร้าง node ใหม่
- Learning rate : จะมีค่าระหว่าง 0 ถึง 1 โดยเราสามารถกำหนดขนาดขั้นตอนของการ train โดยในข้อมูลนี้เราจะกำหนดค่าเหล่านี้ตาม AzureML กำหนดมาแล้ว อัตราที่น้อยกว่าจะใช้เวลานานกว่าในการเข้าถึงวิธีการแก้ปัญหา แต่มีความแม่นยำเพิ่มขึ้น
- Number of trees constructed : ยิ่งค่ามาก ความถูกต้องยิ่งมาก และใช้เวลามากเช่นเดียวกัน
- Random Seed : เราสามารถใส่เลขอะไรก็ได้เพื่อให้การสุ่มในทุก ๆ ครั้งได้เลขเดิมโดยในที่นี่เราจะใส่ 123
โดยในข้อมูลนี้เราจะกำหนดค่าเหล่านี้ตาม AzureML กำหนดมาแล้วยกเว้น Minimum number of samples per leaf node เราใส่เป็น 5
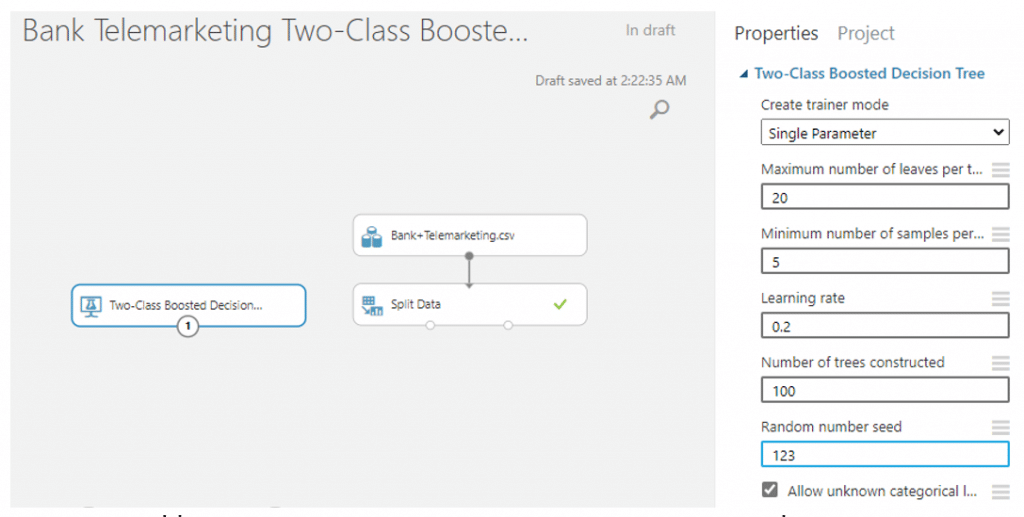
จากนั้นค้นหา module ที่ชื่อว่า Train Model ลากมาวางบน Workspace และลากเส้นเชื่อมจาก Two-Class Decision Forest มาเชื่อมกับวงกลมวงแรกและลากจากวงกลมวงแรกอง Split Data มาเชื่อมวงกลมวงที่สองของ Train Model จากนั้นเลือกคอลัมน์ y
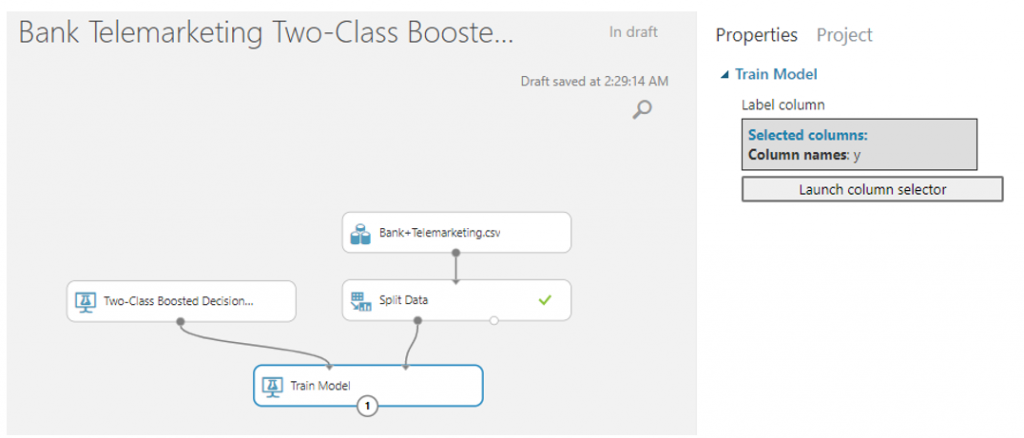
จากนั้นค้นหา module ที่ชื่อว่า Score Model มาวางบน Workspace แล้วลากเส้นเชื่อมจาก Train Model มาเชื่อมที่วงกลมวงแรก และลากจากวงกลมที่สองของ Split Data มาเชื่อมกับวงที่สองของ Score Model
จากนั้นค้นหา module ที่ชื่อว่า Evaluate Model มาวางบน Workspace แล้วลากเส้นเชื่อมจาก Score Model มาที่ Evaluate Model เพื่อดูประสิทธิภาพของโมเดลของเรา จากนั้นกด RUN
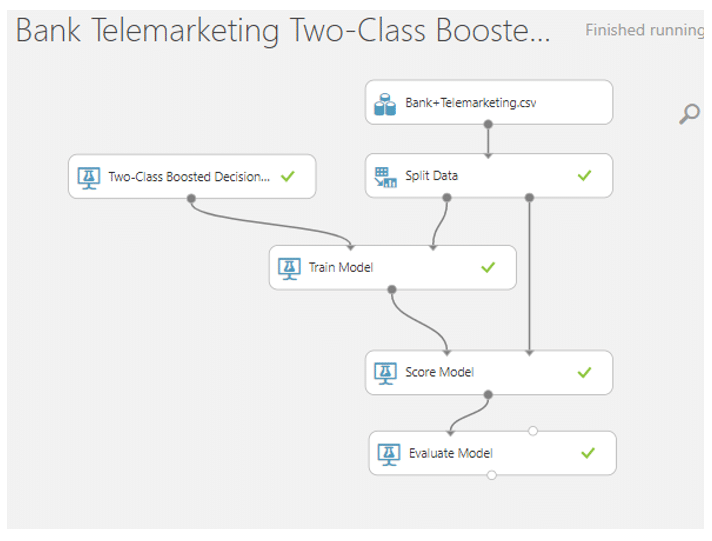
เมื่อเรา Visualize จะพบว่า มีความถูกต้องในการคาดการณ์ว่าลูกค้าลูกค้าจะสมัครรับสินค้าของธนาคารหรือไม่ ซึ่งสามารถคาดการณ์ได้ถูกต้องถึง 0.916 หรือเท่ากับ 96.1% นั้นคือ โมเดล Two-Class Boosted Decision Tree มีความเหมาะสมและมีประสิทธิภาพในการคาดการณ์ว่าข้อมูลแบบไหนลูกค้าจะตอบรับสมัครรับสินค้าและข้อมูลที่ลูกค้าที่เรามีจะมีลูกค้าคนไหนที่มีแนวโน้มจะสมัครรับสินค้าบ้าง ซึ่งช่วยให้เราสามารถทำการเสนอขายหรือการทำการตลาดทางโทรศัพท์ได้อย่างตรงจุดมากยิ่งขึ้น
Fusion ให้บริการวิเคราห์และออกแบบระบบ Machine Learning ด้วยเครื่องมือ ของ
Microsoft Azure
02-440-0408 / sales@fusionsol.com
Link to Implement Azure , Implement Power BI



