บทที่ 13-SMOTE with AzureML
วิธีการจัดการกับ Dataset ที่ไม่สมดุลกันด้วย SMOTE โดยใช้ AzureML
ในกระบวนการเตรียมข้อมูลปัญหาที่เราสามารถพบได้และเราควรทำการแก้ไขมันคือ การที่ dataset มีจำนวนไม่สมดุลกัน เช่น ข้อมูลแรกมี 99 % และอีกข้อมูลมี 1% ซึ่งการที่จำนวนข้อมูล 2 class ทำให้ผลจากการ classify เกิดการทำนายที่ลำเอียด และความแม่นยำที่อาจทำให้เราเข้าใจผิดได้ ซึ่งข้อมูลที่เป็นแบบนี้ตัวอย่างเช่น การฉ้อโกงบัตรเครดิต ข้อบกพร่องในการผลิต การวินิจฉัยโรคที่หาอยาก ภัยพิบัติทางธรรมชาติ การลงทะเบียนกับสถาบันชั้นนำ
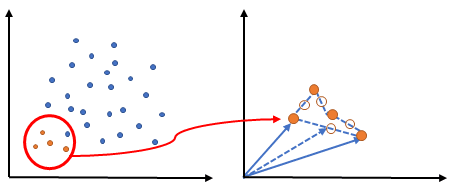
ซึ่งวิธีการแก้ปัญหาเล่านี้เราจะทำได้โดยการเพิ่มเสียงส่วนน้อยหรือลดเสียงส่วนใหญ่ซึ่งวิธีการเพิ่มเสียงส่วนน้อยเราสามารถทำได้โดยการใช้วิธีที่เรียกว่า Synthetic Minority Oversampling Technique (SMOTE) ซึ่งมีวิธีการคือ
- ระบุ feature vector และ จุดที่ใกล้ที่สุด
- ใช้ความแตกต่างระหว่างทั้งสอง
- คูณความแตกต่างด้วยตัวเลขสุ่มระหว่าง 0 ถึง 1
- ระบุจุดใหม่บนส่วนของเส้นตรงโดยการเพิ่มหมายเลขสุ่มลงใน feature vector
- ทำซ้ำขั้นตอนสำหรับ feature vector ที่ระบุ
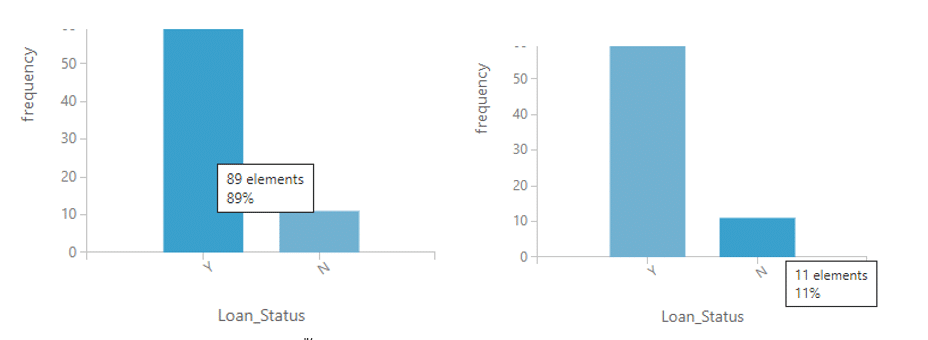
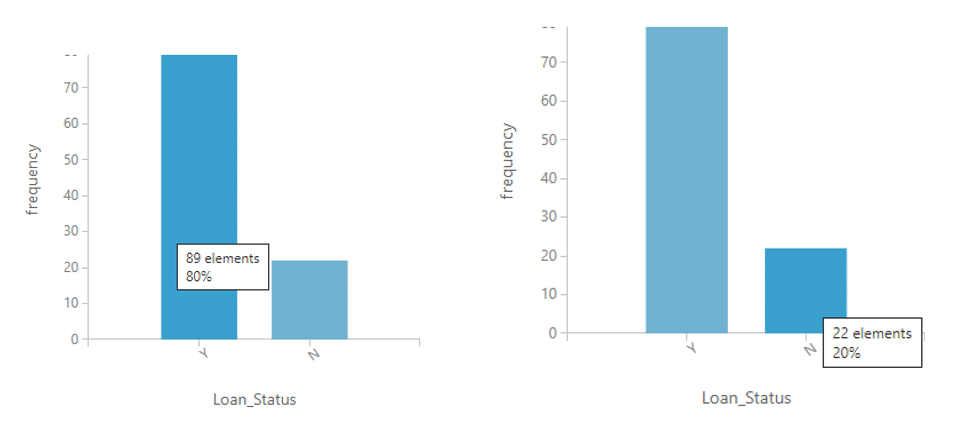
โดยตัวอย่างที่เราต้องการทำ SMOTE ในวันนี้คือ LoanSMOTE ซึ่งมีจำนวน 100 แถวและ 13 คอลัมน์ โดยที่คอลัมน์ Loan_Status มีค่า Y ถึง 89 ค่าหรือ 89% และมีค่า N แค่ 11 ค่าหรือ 11% ดังรูป
โดยเราสามารถทำ SMOTE ได้ดังนี้
- นำข้อมูล LoanSMOTE มาวางบน workspace
- นำ module ที่ชื่อว่า SMOTE วางเชื่อมกับ dataset ของเรา
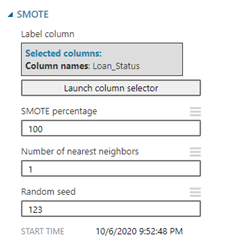
- เลือกคอลัมน์ Loan_Status และทำการตั้งค่า parameter ต่าง ๆ ดังรูป จากนั้นคลิก RUN
เมื่อเรา visualize ดูจะพบว่าข้อมูลของเราเพิ่มเป็น 111 แถวและเรายังพบอีกว่าข้อมูล Y จะมีจำนวนข้อมูลเท่าเดิม แต่ % ลดลงเป็น 80% และจำนวนข้อมูล N เพิ่มขึ้นเป็น 22 ค่า หรือ 20% เท่านี้เราก็ได้ขนาดข้อมูลที่เราต้องการแล้วค่ะ
Fusion ให้บริการวิเคราห์และออกแบบระบบ Machine Learning ด้วยเครื่องมือ ของ
Microsoft Azure
02-440-0408 / sales@fusionsol.com
Link to Implement Azure , Implement Power BI