บทที่ 17-Multiclass Logistic Regression
วิธีการ Classification คุณภาพของไวน์ด้วยโมเดล Multiclass Logistic Regression โดย AzureML
Logistic Regression คือหนึ่งในโมเดลทาง Machine Learning และเป็นโมเดลแบบ Supervised Leaning ที่มีประสิทธิภาพในการการทำ Classification โมเดลหนึ่งที่สามารถแยกประเภทข้อมูลออกจากกันโดยใช้ feature ต่าง ๆ ที่เกี่ยวข้องโดยสามารถแยกข้อมูล 2 ประเภทออกจากกันใน AzureML ได้โดยใช้ module ที่มีชื่อว่า Two-Class Logistic Regression แต่ในบทความนี้เราจะไม่ได้ทำการ Classification ข้อมูลเป็นสองกลุ่มแต่เราจะทำการแยกประเภทมากกว่าสองกลุ่มโดยใช้ Multiclass Logistic Regression
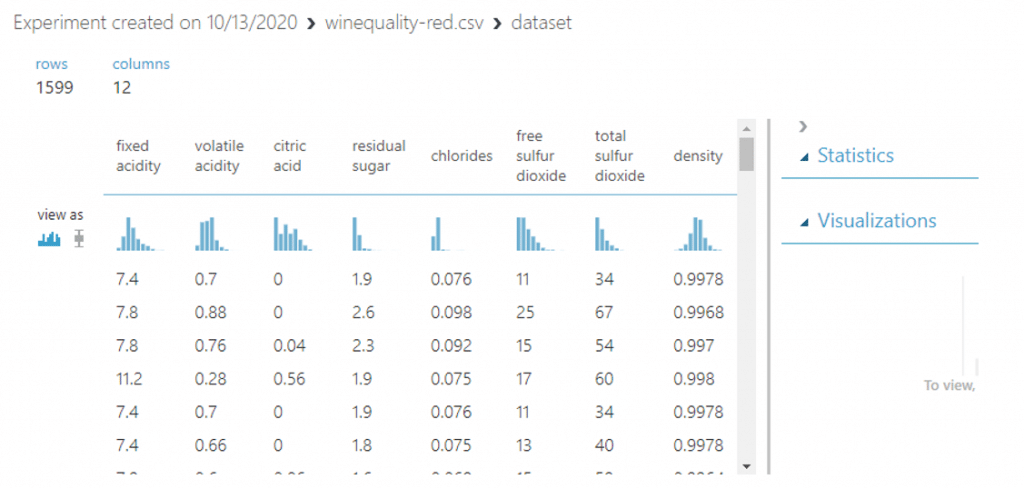
ข้อมูลที่เราต้องการจะทำ Classification โดยใช้ Multiclass Logistic Regression ใน AzureML มาช่วยในการแยกคุณภาพของไวน์ที่เราต้องการซึ่ง มีจำนวนข้อมูล 1599 แถวและ 12 คอลัมน์ โดย 11 คอลัมน์แรกเป็น feature ที่ช่วยในการแยกประเภทและ คอลัมน์ quality คือคอลัมน์ที่เราต้องการแยกประเภทไวน์ออกจากกัน
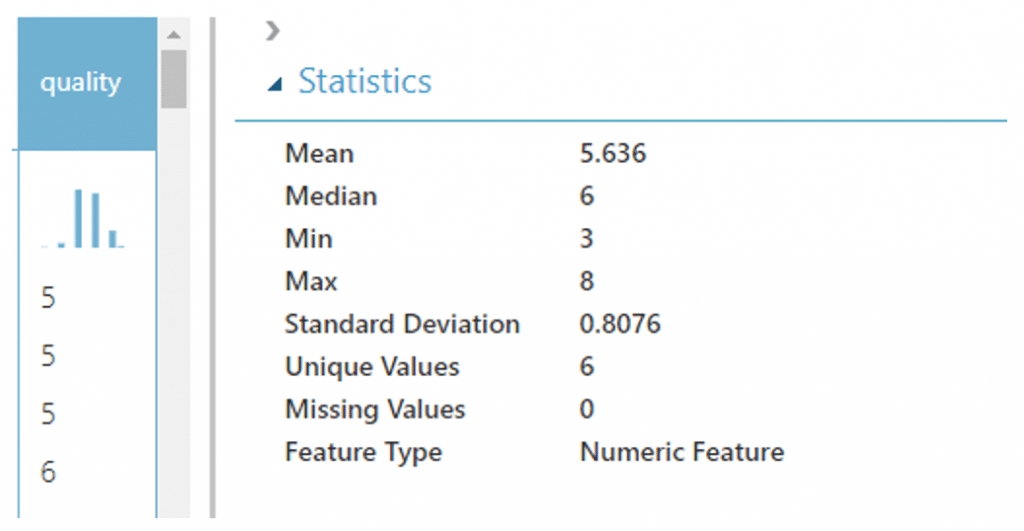
โดยคุณภาพของไวน์จะถูกกำหนดให้เป็นเลขตั้งแต่ 3-8 โดย 3 แทนไวน์คุณภาพต่ำ และ 8 แทนไวน์คุณภาพสูง จากการแบ่งคุณภาพของไวน์แบบนี้ทำให้เราต้องทำการ Classification คุณภาพของข้อมูลออกเป็น 6 กลุ่มซึ่งอาจทำให้ผลของการทำ Classification ออกมาไม่ดีเท่าที่ควรซึ่งในความเป็นจริงคุณภาพของไวนเหล่านี้สามารถจักกลุ่มรวมกันใหม่ได้ดังนี้
- คุณภาพไวน์ที่มีค่าเป็น 3 และ 4 แทนไวน์คุณภาพต่ำ
- คุณภาพไวน์ที่มีค่าเป็น 5 และ 6 แทนไวน์คุณภาพตามค่าเฉลี่ยทั่วไป
- คุณภาพไวน์ที่มีค่าเป็น 7 และ 8 แทนไวน์คุณภาพสูง
การที่เราจัดกลุ่มแบบนี้ทำให้การทำ Classification ของเรามีประสิทธิภาพสูงมากยิ่งขึ้น โดยในบทความนี้นอกจากแสดงวิธีการทำ Multiclass Logistic Regression แล้วนั้น เราจะทำการเปรียบบเทียบการแยกคุณภาพของไวน์ออกเป็น 6 กลุ่มกับการแปลงเป็น 3 กลุ่ม แบบไหนจะมีประสิทธิภาพในการ classify คุณภาพของไวน์มากกว่ากัน
เราจะเริ่มการทำ Multiclass Logistic Regression โดยการแปลงข้อมูลคุณภาพของไวน์เป็น 3 กลุ่มซึ่งสามารถทำได้ ดังนี้
- นำข้อมูลจากเครื่องเข้ามาที่ AzureML โดยกด NEW ตามด้วย DATASET คลิก From local File เพื่อเลือกข้อมูลที่อยู่ในเครื่องของเราเข้ามา จากนั้นเลือกนามสกุลไฟล์ และเลือกว่าไฟล์ที่เรานำเข้ามาต้องการให้มี header หรือชื่อคอลัมน์ไหมตามที่เราต้องการ และกดตรงเครื่องหมายถูก
- ลากข้อมูลที่เราต้องการ Clean หรือต้องการสร้างโมเดลมาไว้บน Workspace โดยนำข้อมูลที่เรานำเข้ามาจาก Saved Dataset เลือก My Datasets จากนั้นลากชุดข้อมูลที่เราต้องการมาไว้บน Workspace
- จากนั้นเราจะดูรายละเอียดของชนิดของข้อมูลโดยการคลิกขวาที่วงกลมเล็ก ๆ ใต้ชุดข้อมูลที่เรานำมาวาง แล้วเลือก Visualize เพื่อดูรายละเอียดของข้อมูล พบว่า ไม่มี missing data และไม่มีคอลัมน์ไหนที่ชนิดข้อมูลไม่ถูกต้อง
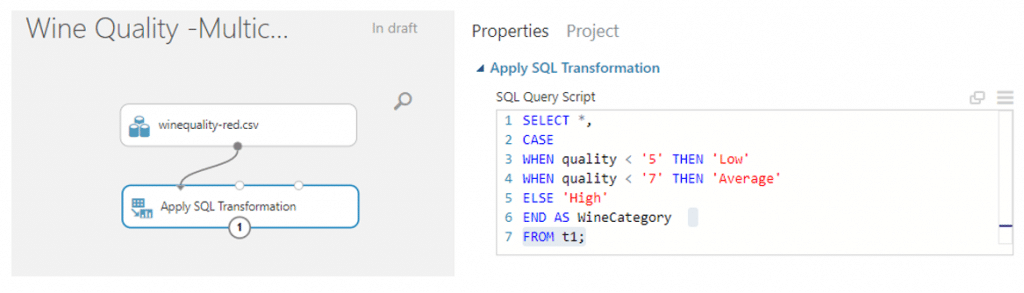
- ทำการแปลงข้อมูลคุณภาพของไวน์ให้อยู่ในรูปที่เราต้องการโดยใช้ module ที่มีชื่อว่า Apply SQL Transformation แล้วเราจะพิมพ์โคด SQL เพื่อข้อมูลจัดให้อยู่ในรูปที่เราต้องการแล้วคลิก RUN
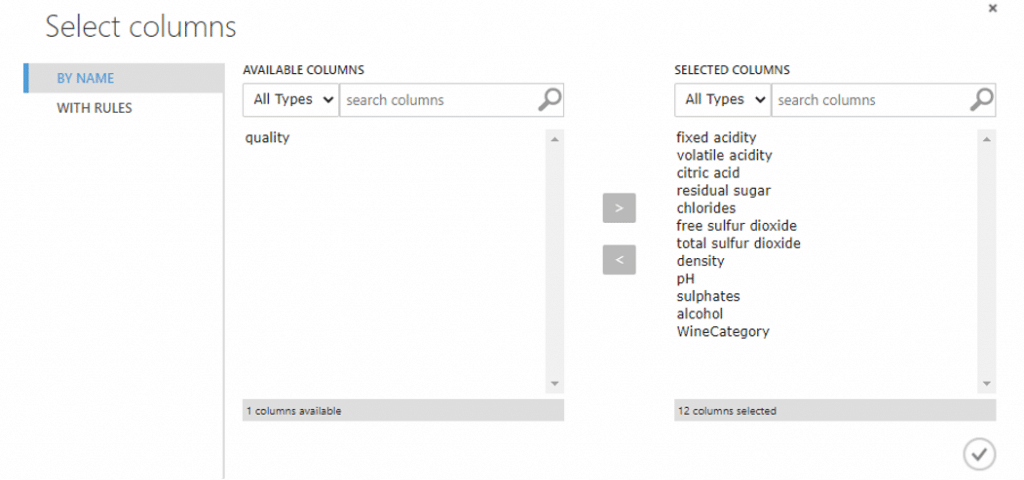
- เลือกคอลัมน์ที่นำมาใช้ในการวิเคราะยกเว้น quality เนื่องจากเราแปลงข้อมูลให้อยู่ในรูปที่เราต้องการในคอลัมน์ WineCategory เรียบร้อยแล้ว โดยการค้นหา module ที่ชื่อว่า Select columns in dataset แล้วคลิก Launch column selector โดยเลือกทุกแถวยกเว้น quality แล้วคลิก RUN
- จากนั้นเราจะแยกข้อมูลออกเป็น training set เพื่อใช้ในการ train ข้อมูลและ test set เพื่อทดสอบข้อมูลสามารถทำได้โดยการค้นหา module ที่มีชื่อว่า Split Data จากนั้นทำการปรับค่า parameter โดยปรับ Fraction of rows in the first output dataset เป็น 0.7 เพื่อแบ่งข้อมูลเป็น training set 70% และ test set 30% และใส่ค่า 123 ใน Random Seed และเลือก Stratified split เลือก true จากนั้นเลือกคอลัมน์ที่เป็น target ของเรานั้นคือ WineCategory จากนั้นคลิก RUN
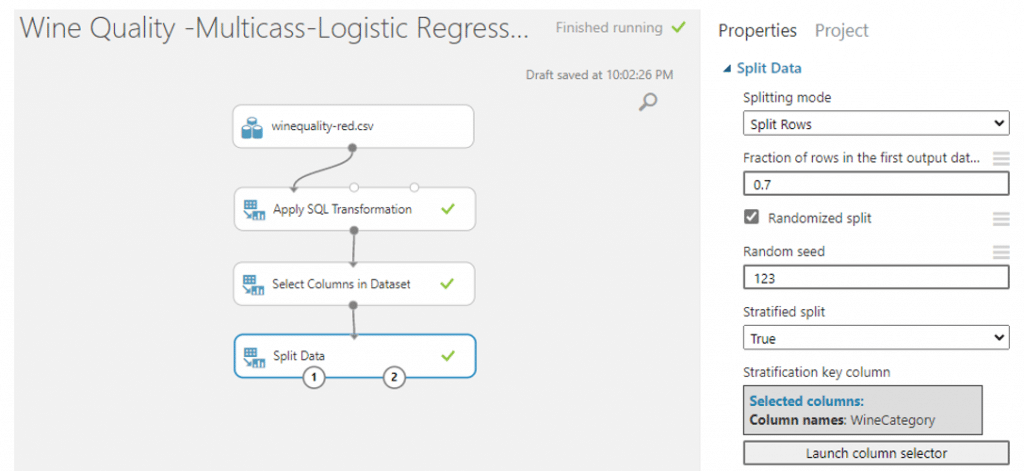
- ค้นหา module ที่มีชื่อว่า Multiclass Logistic Regression เพื่อทำการสร้างและ train โมเดล โดยค่า parameter จะใช้ที่ AzureML กำหนดมา
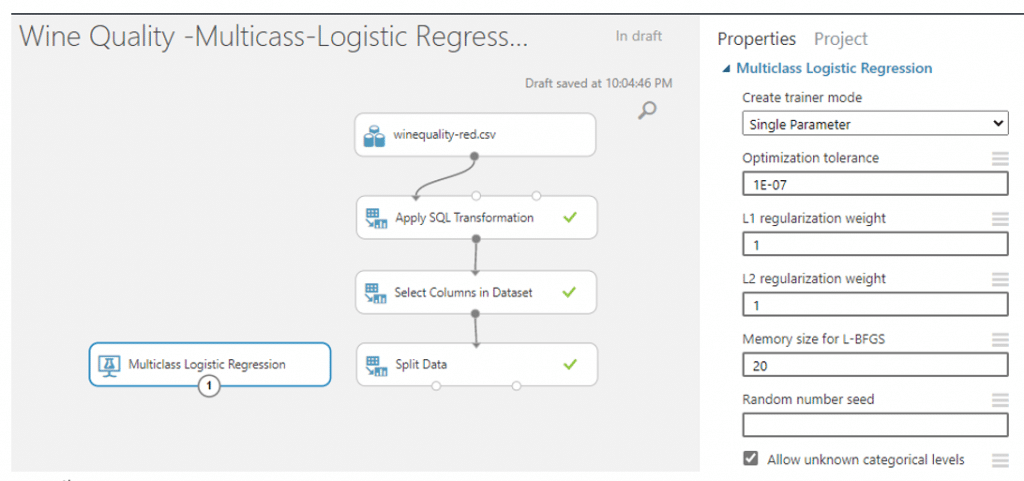
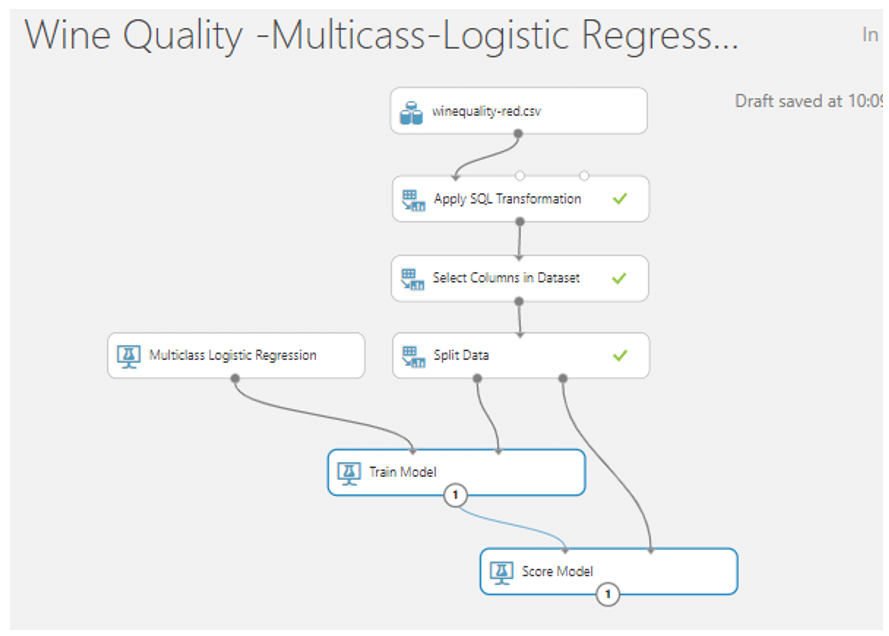
- module ที่ชื่อว่า Train Model ลากมาวางบน Workspace และลากเส้นเชื่อมจาก Two-Class Logistic Regression มาเชื่อมกับวงกลมวงแรกและลากจากวงกลมวงแรกอง Split Data มาเชื่อมวงกลมวงที่สองของ Train Model จากนั้นเลือกคอลัมน์ WineCategory
- จากนั้นค้นหา module ที่ชื่อว่า Score Model มาวางบน Workspace แล้วลากเส้นเชื่อมจาก Train Model มาเชื่อมที่วงกลมวงแรก และลากจากวงกลมที่สองของ Split Data มาเชื่อมกับวงที่สองของ Score Model
- ทำการเปรียบเทียบกับข้อมูลคุณภาพกับข้อมูลที่ไม่มีการแปลงโดยการ Copy ตั้งแต่ Split Data มาเชื่อมกับ winequality-red หรือ dataset ของเรา จากนั้นเปลี่ยนคอลัมน์ที่ module Split Data และTrain Model เป็น quality
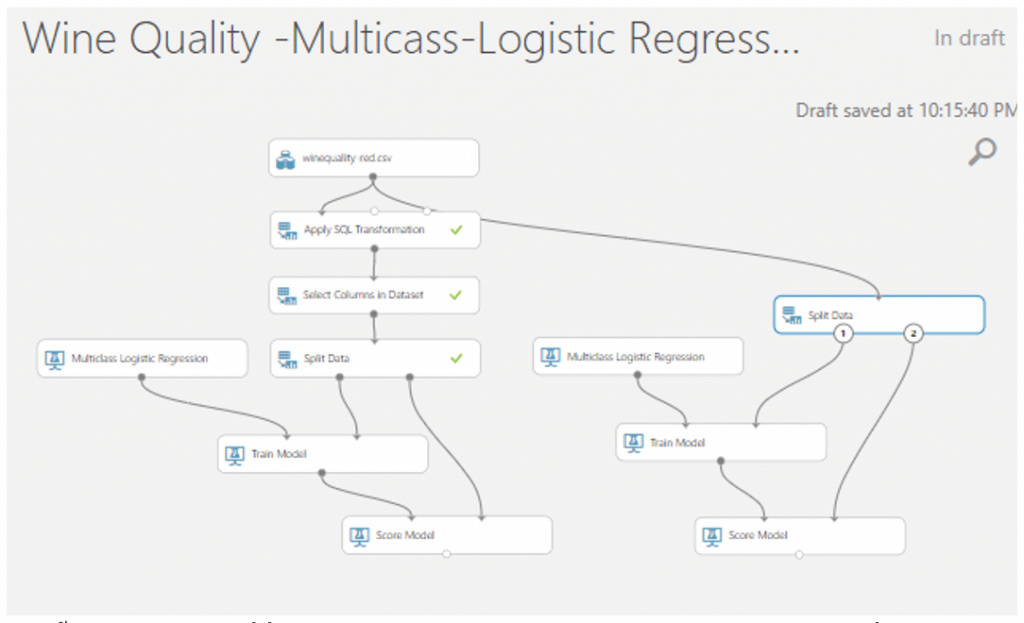
- จากนั้นค้นหา module ที่ชื่อว่า Evaluate Model มาวางบน Workspace แล้วลากเส้นเชื่อมจาก Score Model ของทั้งสองโมเดลมาที่ Evaluate Model เพื่อดูประสิทธิภาพของโมเดลและเปรียบเทียบประสิทธิภาพโมเดลของเรา จากนั้นกด RUN
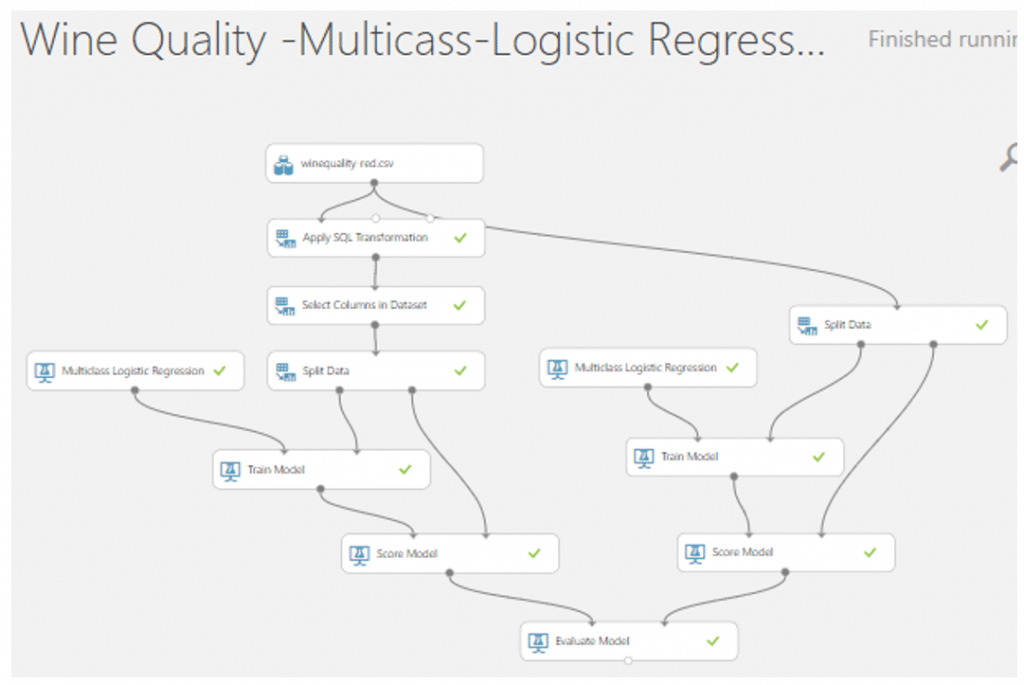
- Visualize ดูประสิทธิภาพของโมเดลจะพบว่าโมเดลที่ทำการแปลงคุณภาพของไวน์ให้เป็น 3 คุณภาพนั้นสามารถ Classify ได้ถูกต้องถึง 0.841667 หรือ 84.1667% ซึ่งมีประสิทธิภาพที่ดีมากในการทำ Classification ในทางกลับกันเมื่อเราแยกประเภทคุณภาพของไวน์ออกเป็น 6 กลุ่มเราจะได้ค่าความถูกต้องแค่ 55.7411% เท่านั้นเนื่องจากบางคุณลักษณะของ feature ที่มีคุณภาพ 3 และ 4, 5 และ 6, 7 และ 8 มีความใกล้เคียงกันนั้นเองค่ะ

Fusion ให้บริการวิเคราห์และออกแบบระบบ Machine Learning ด้วยเครื่องมือ ของ
Microsoft Azure
02-440-0408 / sales@fusionsol.com
Link to Implement Azure , Implement Power BI





