บทที่ 22-Cluster Analysis
วิธีการทำ Clustering หรือ Cluster Analysis ของข้อมูล Call Center ด้วย AzureML
Clustering เป็นโมเดลประเภท Unsupervised Learning โดยเป็นโมเดลที่ใช้ในการจัดกลุ่ม ซึ่งสามารถจัดกลุ่มลูกค้า หรือกลุ่มของสิ่งต่าง ๆ ที่เราต้องการเพื่อสร้างกลยุทธ์ที่จะนำมาใช้กับกลุ่มต่าง ๆ หรือแม้แต่การค้นหากลุ่มที่มีความแตกต่างในฐานข้อมูลลูกค้า โดยข้อมูลหรือ object ที่เป็นกลุ่มเดียวกันเราจะเรียกว่า cluster ซึ่งข้อมูลอยู่ในกลุ่มเดียวกันจะมีลักษณะที่เหมือนกัน
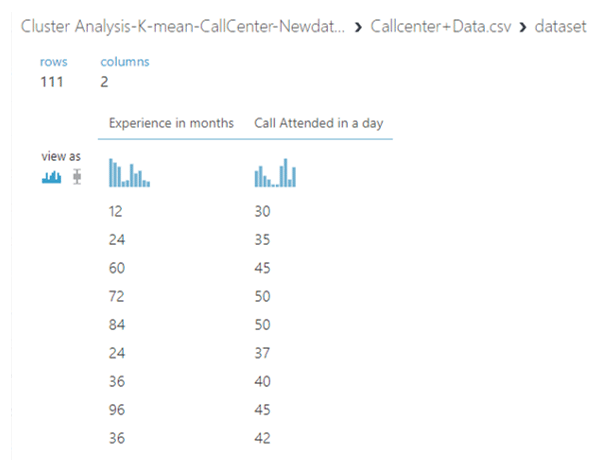
ซึ่งข้อมูลที่เรานำมาทำ Clustering ในวันนี้คือข้อมูล Call Center ที่เราต้องการแบ่งกลุ่มของ data set นี้ออกเป็น 4 กลุ่มเพื่อจะได้นำไปสร้างกลยุทธ์ให้เหมาะสมกับลูกค้าในแต่ละกลุ่ม ข้อมูลเราจะมีทั้งหมด 111 แถว 2 คอลัมน์คือ Experience in months และ Call Attended in a day โดยวิธีการ Clustering ที่เราจะใช้คือ K-means Clustering ซึ่งมีวิธีการดังนี้
- ลากข้อมูล Call Center ที่เราต้องการมาไว้บน Workspace
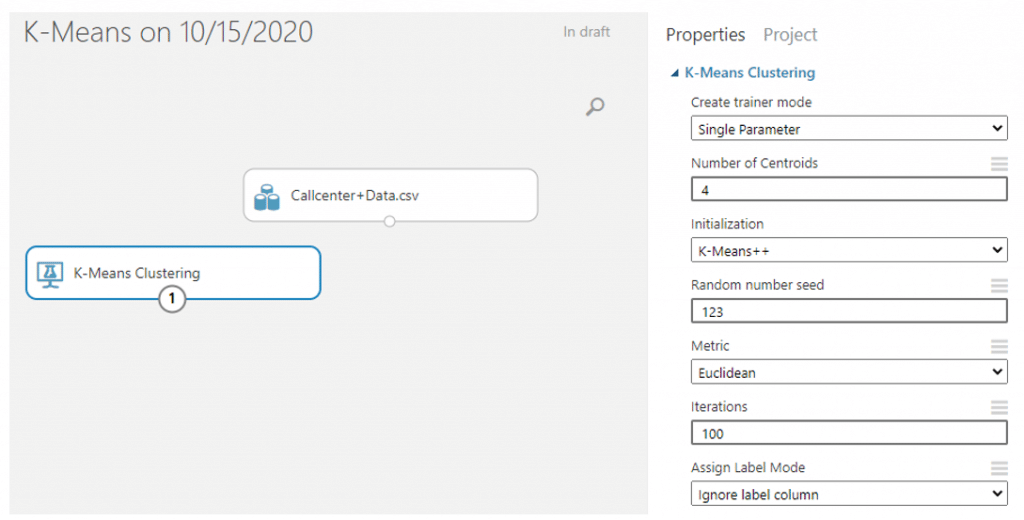
- จากนั้นค้นหา module ที่ชื่อว่า K-means Clustering ซึ่งค่า Parameter แต่ละตัวมีความหมายดังนี้
- Create trainer mode
- Single Parameter : ระบุ set ของค่าเฉพาะ
- Parameter Range : ระบุค่าเฉพาะหลายค่าและรับ set ที่เหมาะสมที่สุดสำหรับกำหนดค่า
- Number of Centroids: จำนวนกลุ่มที่เราต้องการจะแบ่ง
- Initialization
- Random : สุ่มจุดข้อมูลแบบ placement ลงใน clusters
- First N or Forgy Method : สุ่มจุดข้อมูลแรก
- K-means++ : เริ่มต้นด้วยการปรับปรุงการค้นหาวิธีเริ่มต้น
- K-means++ Fast : เหมาะสำหรับการ cluster ที่เร็วขึ้น
- Evenly
- Use Label Column : ใช้การ Label Column
- Random number seed : เราสามารถใส่เลขอะไรก็ได้เพื่อให้การสุ่มในทุก ๆ ครั้งได้เลขเดิมโดยในที่นี่เราจะใส่ 123
- Metric : วิธีการที่ใช้ในคำนวณระยะระหว่างจุด Centroids กับจุดอื่น
- Euclidean : K-Means Algorithm ใช้ตัวนี้
- Cosine
- Iterations : จำนวนการทำซ้ำหรือจำนวนครั้งที่เราต้องการ RUN ข้อมูลของเรา
- Assign Label Mode
- Ignore label column : ค่าใน label column จะถูกละเว้นและไม่ได้ใช้ในการสร้างแบบจำลอง
- Fill missing values : fill missing ค่า label column ใช้ feature เพื่อช่วยสร้าง Clusters และหากแถวใดไม่มี label ใดค่าจะถูกกำหนดโดยใช้ feature อื่น ๆ
- Overwrite from closest to center : ค่า label column จะถูกแทนที่ด้วยค่า label column ที่มาจากการคาดการณ์ โดยใช้ Lebel จุดที่ใกล้เคียงกับจุด Centroids ปัจจุบันของเราที่สุด
- Create trainer mode
เนื่องจากข้อมูลของเราไม่มี label column เราจึงกำหนดค่า parameter ดังนี้
- Create trainer mode : Single Parameter
- Number of Centroids : 4
- Initialization : K-means++
- Random number seed : 123
- Metric : Euclidean
- Iterations : 100 Assign Label Mode : Ignore label column
ค้นหา module ที่ชื่อว่า Train Clustering Model จากนั้นลากเส้นเชื่อมจาก K-means มาที่วงกลมวงแรกและลากเส้นเชื่อมจาก Call Center มาที่วงที่สองและเลือกคอลัมน์ทั้งสองคอลัมน์ จากนั้นคลิก RUN
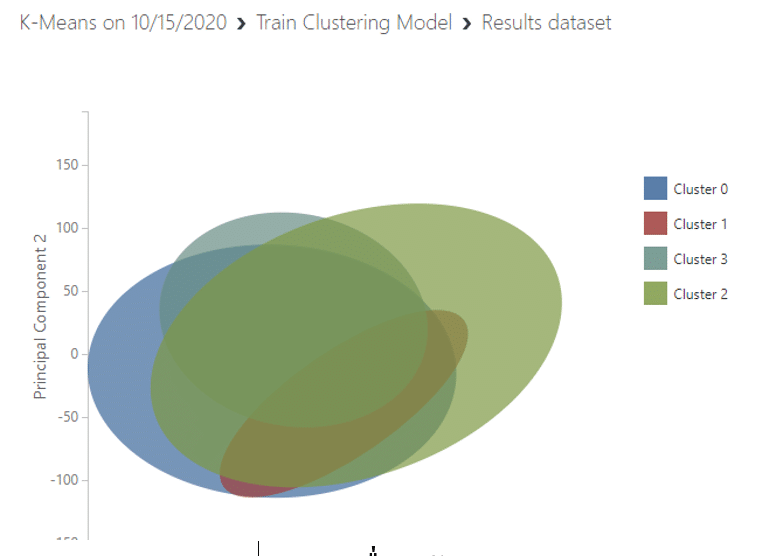
จากนั้นคลิกขวาที่วงกลมด้านล่างวงที่สองของ Train Clustering Model แล้วเลือก visualize เราจะเห็นว่าเราจะได้กราฟที่ข้อมูลถูกแบ่งเป็น 4 กลุ่มแล้วแต่ยังไม่ทราบข้อมูลแต่ละกลุ่ม
นำ module ที่ชื่อว่า Select column in dataset มาเชื่อมกับ Train Clustering Model วงกลมล่างวงที่สอง จากนั้นเลือกทุกคอลัมน์แล้วคลิก RUN
Visualize ดูข้อมูลของเราเราจะเห็นคอลัมน์ที่ชื่อว่า Assignments ซึ่งก็คือ cluster number ที่แยกข้อมูลออกเป็นกลุ่มให้เราเรียบร้อยแต่เรายังไม่รู้ว่าแต่ละกลุ่มมีลักษณะอย่างไรบ้างเพื่อให้วางแผนกลยุทธ์ต่อไป
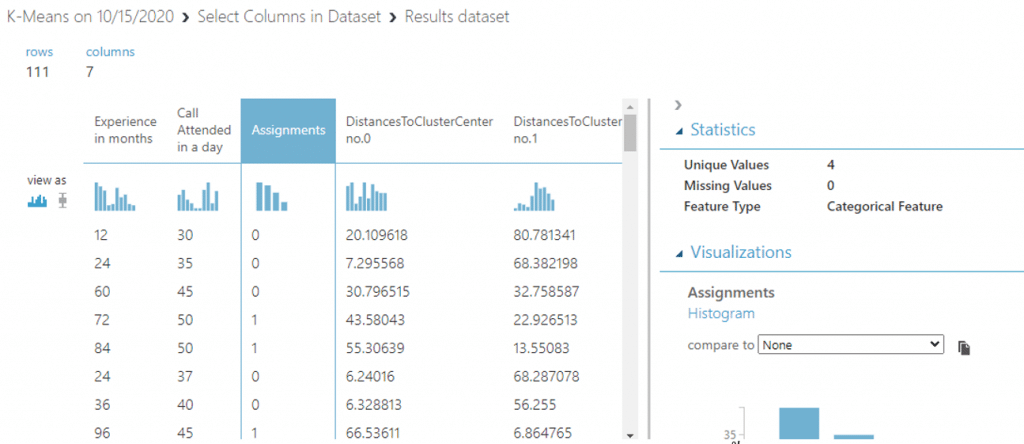
เราจะทำการแยกข้อมูลแต่ละกลุ่มออกจากกันโดยใช้ Split Data จากนั้นเลือก Splitting mode เป็น Relative Expression แล้วพิมพ์ \”Assignments” < 1 เพื่อดูเฉพาะข้อมูลกลุ่มที่ 0 จากนั้นคลิก RUN
โดยข้อมูลที่ visualize ได้จากวงกลมแรกจะเป็นกลุ่มที่ 0 ที่เราต้องการ ส่วนวงที่สองจะเป็นกลุ่มอื่นที่เรายังไม่ได้แยก
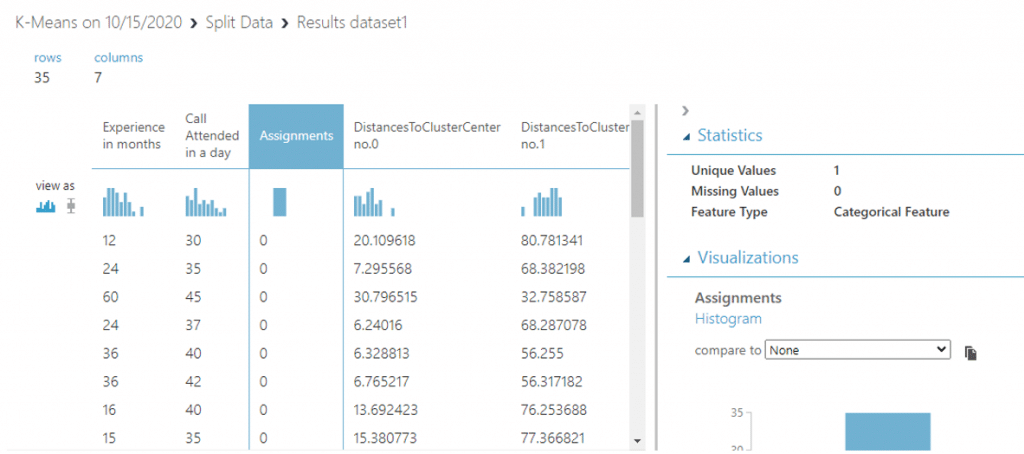
ทำเช่นเดียวกับข้อ 7 แต่เปลี่ยนเป็น \”Assignments” < 2, 3, 4 ตามลำดับ จากนั้นคลิก RUN เราจะได้ข้อมูลแยกตามแต่ละกลุ่มแล้วค่ะ
หากเราต้องการทราบ performance ของการ Clustering เราสามารถทำได้โดย
- นำข้อมูล CallCenter มาวางบน Workspace จากนั้นนำ module ที่ชื่อ Split Data มาเชื่อมกับ dataset ของเราโดยตั้งค่า parameter ดังนี้
- Splitting mode : Split Rows
- Fraction of rows in the first output dataset : 0.7
- Random seed : 123 Stratified split : False
- จากนั้นค้นหา module ที่ชื่อว่า K-means Clustering ซึ่งค่า Parameter จะตั้งค่าเหมือนกันกับวิธีการก่อนหน้า
- ค้นหา module ที่ชื่อว่า Train Clustering Model จากนั้นลากเส้นเชื่อมจาก K-means มาที่วงกลมวงแรกและลากเส้นเชื่อมจาก Split Data มาที่วงที่สองและเลือกคอลัมน์ทั้งสองคอลัมน์
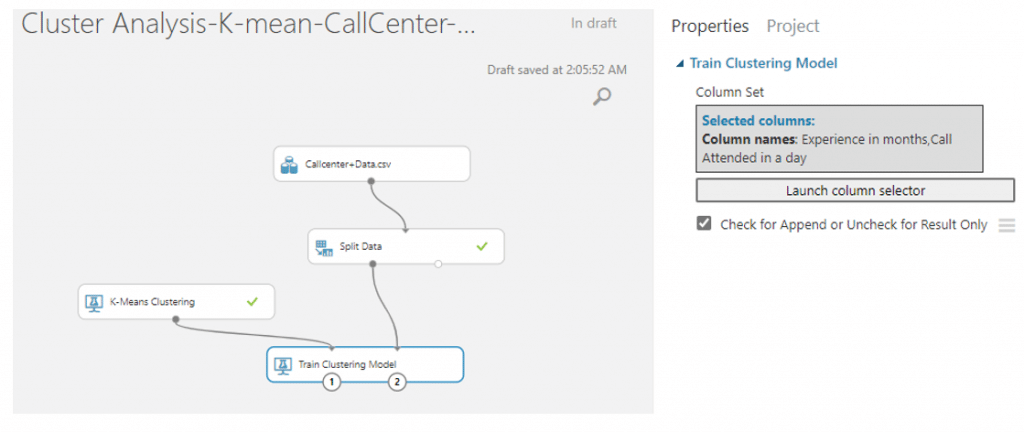
- ค้นหา module ที่ชื่อว่า Assign Data to Clusters จากนั้นลากเส้นเชื่อมจาก Train Clustering Model มาที่วงกลมวงแรก และจาก Spilt Data มาที่วงที่สอง
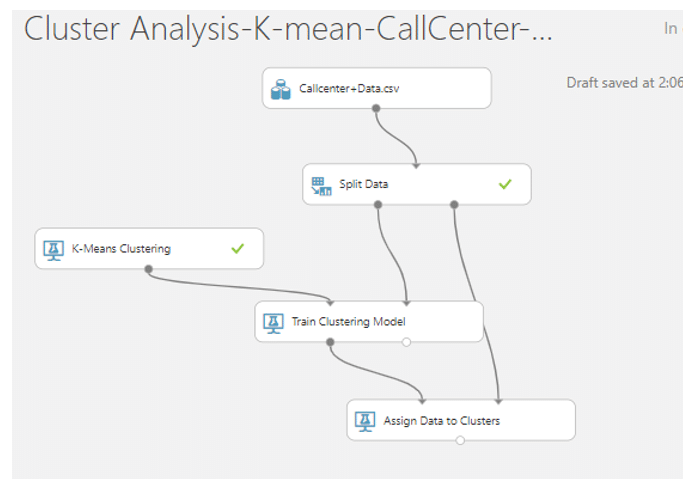
- จากนั้นค้นหา module ที่ชื่อว่า Evaluate Model มาวางบน Workspace แล้วลากเส้นเชื่อมจาก Score Model มาที่ Evaluate Model เพื่อดูประสิทธิภาพของโมเดลของเรา จากนั้นกด RUN
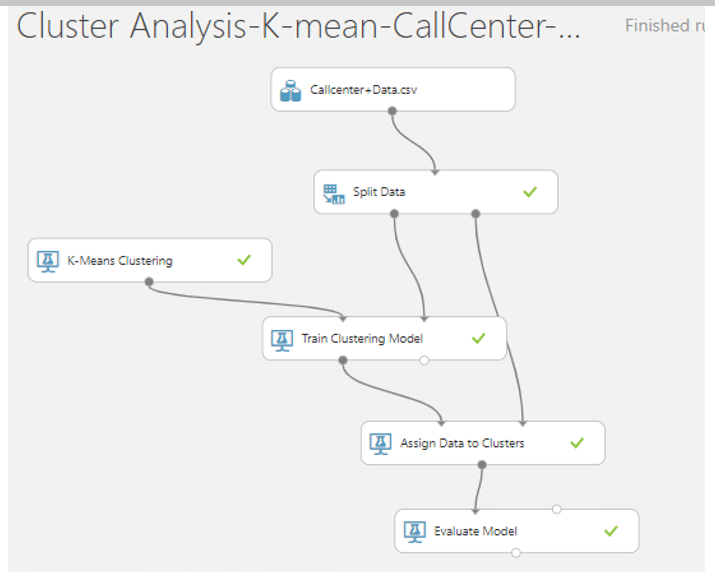
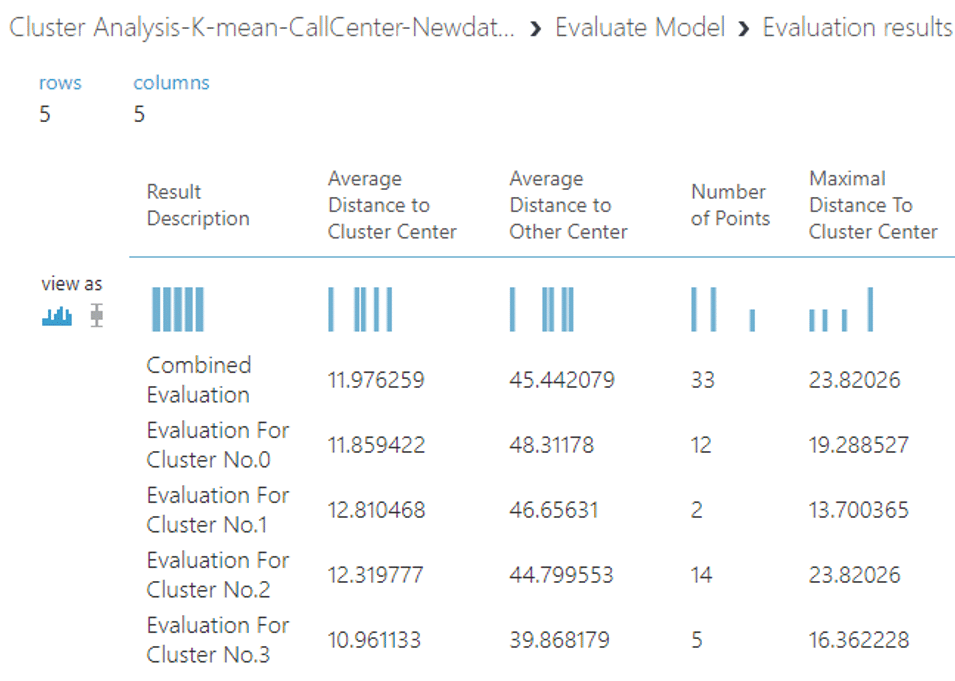
ซึ่งได้ผลลัพธ์ในการทดสอบประสิทธิภาพของโมเดล ดังนี้
Fusion ให้บริการวิเคราห์และออกแบบระบบ Machine Learning ด้วยเครื่องมือ ของ
Microsoft Azure
02-440-0408 / sales@fusionsol.com
Link to Implement Azure , Implement Power BI