Azure Synapse Analytics
Analytics คือ ชุดเครื่องมือใหม่จาก Microsoft ที่ช่วยให้เราทำ Analytics ได้เร็วขึ้น และ เป็นแบบ real time และ ซึ่งรวมชุดเครื่องมือที่รองรับทั้ง Data ที่เป็น Structure and Unstructured
ระบบวิเคราะห์ข้อมูลในแบบเดิม ที่ยังแตกแยกออกเป็นเครื่องมือและกระบวนการหลายขั้นตอน ทำให้วิศวกรข้อมูล (data engineer) นักวิทยาศาสตร์ข้อมูล (data scientist) และนักวิเคราะห์ข้อมูล (data analyst) ต้องพึ่งพาเครื่องมือและแพลตฟอร์มที่แตกต่างกันไปในภารกิจของตนเอง จนทำให้การจัดทำรายงานวิเคราะห์ข้อมูลโดยละเอียดเพียงฉบับเดียว อาจต้องอาศัยการถ่ายโอนข้อมูลปริมาณมหาศาลแบบซ้ำซ้อนไปวิเคราะห์ด้วยเครื่องมือหลายชุดพร้อม ๆ กัน และก่อนที่จะนำมารวมกันเพื่อสรุปเป็นรายงานที่ใช้งานทางธุรกิจได้จริงนั้น ก็อาจต้องอาศัยแรงและเวลาอยู่ไม่น้อยในการเขียนโค้ดใหม่มาผสานทุกอย่างให้เข้ากันได้
Azure Synapse มีรากฐานอยู่บนเอนจินประมวลผลคำสั่ง SQL รุ่นใหม่ ที่ออกแบบขึ้นเพื่อการทำงานบนคลาวด์โดยเฉพาะ รองรับการประมวลผลได้ในหลากหลายสภาวะการใช้งาน นับตั้งแต่ทรัพยากรระบบในระดับแค่หน่วยประมวลผลตัวเดียว ไปจนถึงการกระจายงานสู่โหนดนับพัน ส่วนการผนึกเอา Apache Spark เข้าไว้เป็นส่วนหนึ่งของ Synapse ยังช่วยให้ขั้นตอนการเตรียมความพร้อมของข้อมูลและการวิเคราะห์ด้วย Machine Learning มีศักยภาพที่หลากหลายและครบครันมากยิ่งขึ้น เพิ่มทางเลือกควบคู่ไปกับการใช้งาน SQL
นอกจากนี้ ยังทำงานประสานกับโซลูชั่นข้อมูลของไมโครซอฟท์อย่าง Power BI และ Azure Machine Learning ได้อย่างลงตัว โดยผู้ใช้สามารถใช้งาน Power BI เพื่อสร้างรายงานหรือแดชบอร์ดจากข้อมูลได้จากใน Synapse Studio โดยตรง จึงสามารถเตรียมข้อมูลเพื่อนำเสนอได้อย่างรวดเร็ว ขณะที่ Azure Machine Learning ก็สามารถวิเคราะห์ข้อมูลเพื่อค้นหารูปแบบและคาดการณ์แนวโน้มในอนาคตได้ทันที โดยไม่ต้องถ่ายโอนข้อมูลไปวิเคราะห์ด้วยเครื่องมืออื่น
Fusion Service
- Design Synapse Solution
- Implement DW
- Design Dashboard
- Service Ticket or Outsource

Synapse SQL architecture components
Synapse SQL ใช้ประโยชน์จากสถาปัตยกรรมที่ขยายขนาดออกเพื่อกระจายการประมวลผลข้อมูลทางคอมพิวเตอร์ไปยังโหนดต่างๆ การคำนวณแยกจากที่เก็บข้อมูล ซึ่งช่วยให้คุณสามารถปรับขนาดการคำนวณโดยไม่ขึ้นกับข้อมูลในระบบของคุณ
Dedicate SQL Pool คือการทำงานในลักษณะที่กำหนด จำนวน Server ไว้ชัดเจน
Serverless SQL Pool การปรับขนาดจะทำโดยอัตโนมัติเพื่อรองรับความต้องการทรัพยากรการสืบค้น เมื่อโทโพโลยีเปลี่ยนแปลงไปตามกาลเวลาโดยการเพิ่ม การลบโหนด หรือเฟลโอเวอร์ โทโพโลยีจะปรับให้เข้ากับการเปลี่ยนแปลงและทำให้แน่ใจว่าการสืบค้นของคุณมีทรัพยากรเพียงพอและเสร็จสิ้นได้สำเร็จ ตัวอย่างเช่น รูปภาพด้านล่างแสดงพูล SQL แบบไร้เซิร์ฟเวอร์ที่ใช้โหนดประมวลผล 4 โหนดเพื่อดำเนินการค้นหา
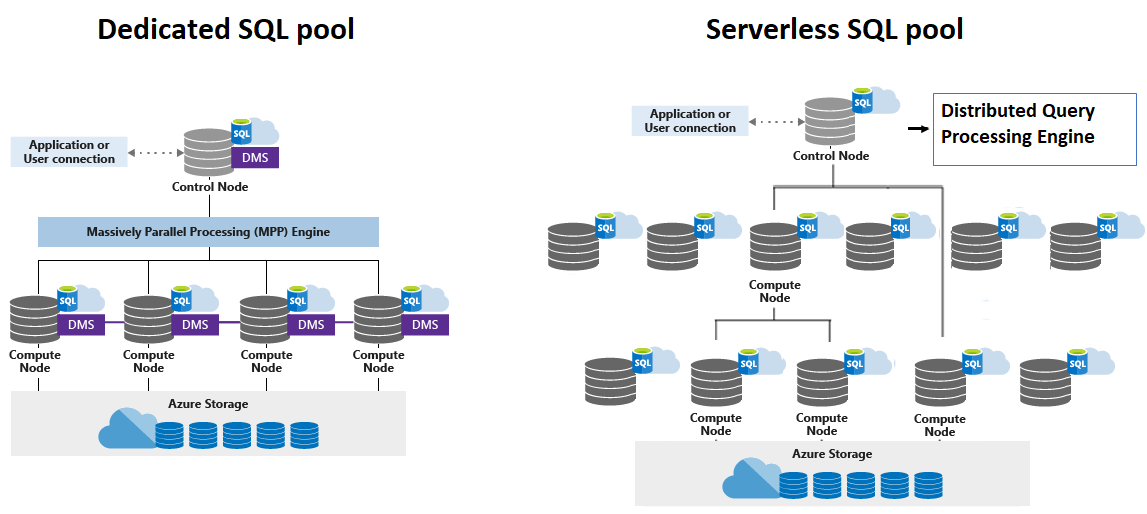
Synapse SQL ใช้สถาปัตยกรรมแบบโหนด แอปพลิเคชันเชื่อมต่อและออกคำสั่ง T-SQL กับโหนดควบคุม ซึ่งเป็นจุดเข้าใช้งานเพียงจุดเดียวสำหรับ Synapse SQL
โหนด Azure Synapse SQL Control ใช้เครื่องมือการสืบค้นแบบกระจายเพื่อเพิ่มประสิทธิภาพการสืบค้นสำหรับการประมวลผลแบบขนาน แล้วส่งผ่านการดำเนินการไปยังโหนด Compute เพื่อทำงานแบบคู่ขนานกัน
โหนดควบคุมพูล SQL แบบไร้เซิร์ฟเวอร์ใช้กลไกการประมวลผลการสืบค้นแบบกระจาย (DQP) เพื่อปรับให้เหมาะสมและจัดการการดำเนินการแบบกระจายของการสืบค้นผู้ใช้โดยแยกออกเป็นการสืบค้นที่มีขนาดเล็กลงซึ่งจะถูกดำเนินการบนโหนดคอมพิวเตอร์ แต่ละแบบสอบถามขนาดเล็กเรียกว่างานและแสดงถึงหน่วยการดำเนินการแบบกระจาย อ่านไฟล์จากที่เก็บข้อมูล รวมผลลัพธ์จากงานอื่น กลุ่ม หรือข้อมูลคำสั่งซื้อที่ดึงมาจากงานอื่น
โหนดประมวลผลเก็บข้อมูลผู้ใช้ทั้งหมดใน Azure Storage และเรียกใช้การสืบค้นแบบขนาน Data Movement Service (DMS) เป็นบริการภายในระดับระบบที่ย้ายข้อมูลข้ามโหนดตามความจำเป็นเพื่อเรียกใช้การสืบค้นแบบขนานและส่งคืนผลลัพธ์ที่ถูกต้อง
ด้วยพื้นที่จัดเก็บและการประมวลผลแบบแยกส่วน เมื่อใช้ Synapse SQL ผู้ใช้จะได้รับประโยชน์จากการปรับขนาดพลังประมวลผลที่เป็นอิสระโดยไม่คำนึงถึงความต้องการพื้นที่จัดเก็บของคุณ สำหรับการปรับขนาดพูล SQL แบบไร้เซิร์ฟเวอร์จะทำโดยอัตโนมัติ ในขณะที่สำหรับพูล SQL เฉพาะ สามารถทำได้ดังนี้
- ขยายหรือย่อพลังการประมวลผลภายในพูล SQL เฉพาะ โดยไม่ต้องย้ายข้อมูล
- หยุดความจุในการประมวลผลชั่วคราวโดยปล่อยให้ข้อมูลไม่เสียหาย ดังนั้นคุณจะจ่ายเฉพาะพื้นที่เก็บข้อมูลเท่านั้น
- ดำเนินการประมวลผลต่อในช่วงเวลาทำการ

โครงสร้างของ Synapse
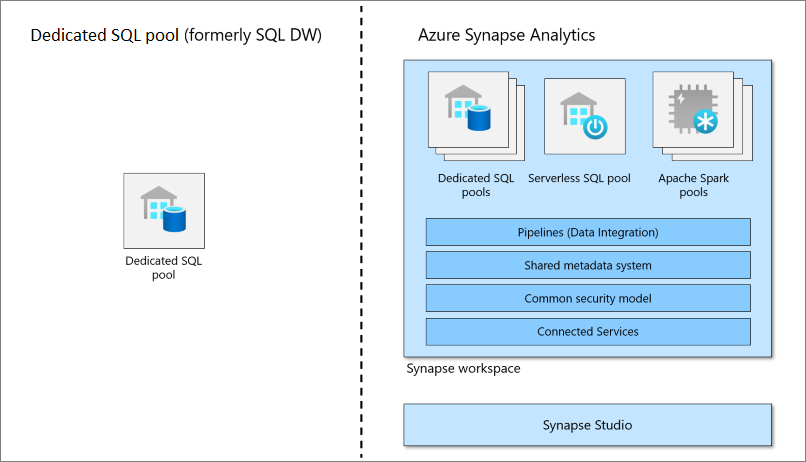
ในโซลูชันข้อมูลบนระบบคลาวด์ ข้อมูลจะถูกนำเข้าไปยังพื้นที่เก็บข้อมูลขนาดใหญ่จากแหล่งต่างๆ เมื่ออยู่ในที่เก็บข้อมูลขนาดใหญ่ อัลกอริธึม Hadoop, Spark และแมชชีนเลิร์นนิงจะเตรียมและฝึกอบรมข้อมูล เมื่อข้อมูลพร้อมสำหรับการวิเคราะห์ที่ซับซ้อน พูล SQL เฉพาะจะใช้ PolyBase เพื่อสืบค้นที่เก็บข้อมูลขนาดใหญ่ PolyBase ใช้การสืบค้น T-SQL มาตรฐานเพื่อนำข้อมูลไปยังตาราง SQL pool เฉพาะ (เดิมคือ SQL DW)
พูล SQL เฉพาะ (เดิมคือ SQL DW) จัดเก็บข้อมูลในตารางเชิงสัมพันธ์พร้อมที่เก็บข้อมูลแบบคอลัมน์ รูปแบบนี้ช่วยลดต้นทุนการจัดเก็บข้อมูลได้อย่างมาก และปรับปรุงประสิทธิภาพการสืบค้น เมื่อจัดเก็บข้อมูลแล้ว คุณสามารถเรียกใช้การวิเคราะห์ในวงกว้างได้ เมื่อเทียบกับระบบฐานข้อมูลแบบเดิม แบบสอบถามการวิเคราะห์จะเสร็จสิ้นในไม่กี่วินาทีแทนที่จะเป็นนาที หรือชั่วโมงแทนที่จะเป็นวัน
ผลการวิเคราะห์สามารถไปที่ฐานข้อมูลหรือแอปพลิเคชันการรายงานทั่วโลก นักวิเคราะห์ธุรกิจสามารถรับข้อมูลเชิงลึกเพื่อทำการตัดสินใจทางธุรกิจที่มีข้อมูลครบถ้วน
Azure Synapse มอบความรวดเร็วและคล่องตัวในการทำงานกับข้อมูลทั้งในรูปแบบ Data Lake และ Data Warehouse บนแพลตฟอร์มเดียว พร้อมรองรับการทำงานกับหลากหลายระบบฐานข้อมูลที่องค์กรอาจมีอยู่เดิม ผ่านเครื่องมือหนึ่งเดียวอย่าง Studio ที่ใช้งานได้หลายแบบ ทั้งด้วยการเขียนโค้ดเป็นหลักในแบบที่คนทำงานกับข้อมูลคุ้นเคยดี และแบบที่ไม่ต้องเขียนโค้ดเลย ซึ่งอาจตอบโจทย์บุคลากรในสายธุรกิจมากกว่า โดยท้ายที่สุดแล้ว สามารถย่นย่อเวลาในการเปลี่ยนข้อมูลให้กลายเป็นทรัพยากรประกอบการตัดสินใจ จากเดิมที่อาจต้องใช้เวลาหลายอาทิตย์หรือหลายเดือน ให้เห็นผลได้ภายในไม่กี่วันเท่านั้น
Reference





