บทที่ 8-How to remove duplicate employee by AzureML
วิธีการลบข้อมูลที่ซ้ำกันง่าย ๆ ด้วย AzureML
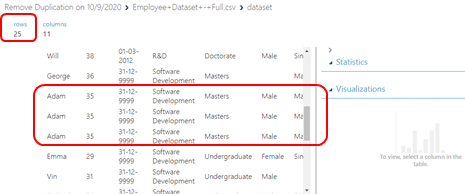
กระบวนการเตรียมข้อมูลก่อนนำไปสร้างโมเดลนั้นเป็นกระบวนการที่ใช้เวลานานที่สุดเนื่องจากชุดข้อมูลที่เราได้มานั้นไม่ได้อยู่ในรูปแบบที่สมบูรณ์และหนึ่งในปัญหาของกระบวนการเตรียมข้อมูลคือ การที่มีข้อมูลซ้ำกันหรือที่เรียกว่า Duplication ซึ่งมีส่งผลกับกระบวนการผลของ Train ของโมเดล ทำให้เราต้องจัดการกับข้อมูลที่ซ้ำกันหล่านี้ก่อนการสร้างโมเดลนั้นเองค่ะ โดยมีตัวอย่างของข้อมูลที่ซ้ำกัน ดังรูป
โดยเราสามารถจัดการกับข้อมูลที่ Duplication ได้ง่าย ๆ โดยใช้ AzureML ดังนี้
ลากข้อมูลที่เราต้องการลบแถวที่ซ้ำกันหรือต้องการสร้างโมเดลมาไว้บน Workspace โดยนำข้อมูลที่เรานำเข้ามาจาก Saved Dataset เลือก My Datasets หรือจากนั้นลากชุดข้อมูลที่เราต้องการมาไว้บน Workspace และหากเราต้องการนำเข้าข้อมูลในรูปแบบอื่น เช่น นำเข้าข้อมูลจากเว็บ เราก็เลือก module นั้นมาวางได้เลย
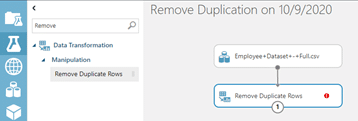
หา Module ที่ชื่อว่า Remove Duplicate row แล้วลากมาวางบน Workspace จากนั้นลากเส้นเชื่อม Module กับชุดข้อมูลของเรา
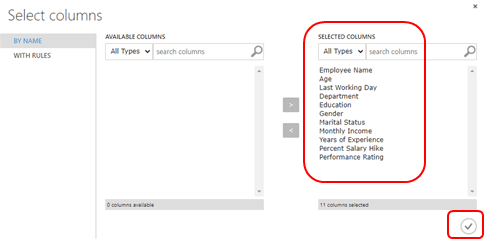
กด Launch column selector แล้วเลือกคอลัมน์ที่มีข้อมูลซ้ำกันหรือเลือกทุกคอลัมน์จะดีที่สุดเพราะระบบจะเลือกลบแถวที่มีข้อมูลเหมือนกันทุกตัวออก โดยเลือกทุกคอลัมน์มาไว้ที่ Selected column แล้วกดเครื่องหมายถูก
ข้อควรระวังหากเราเลือกบางคอลัมน์ระบบจะทำการลบแถวที่มีข้อมูลคอลัมน์นั้นซ้ำกันออกซึ่งข้อมูลอาจถูกลบมากกว่าที่เราต้องการออกไปด้วยค่ะ
เมื่อเราเลือกคอลัมน์เรียบร้อยแล้วจึงกด RUN และเมื่อเรา Visualize ดูจะพบว่าข้อมูลแถวที่ซ้ำกันเหล่านั้นถูกลบให้เหลือแถวเดียวที่เราจะนำไปใช้วิเคราะห์ต่อ สังเกตจากจำนวนแถวที่ลดลงเหมือนในตัวอย่างที่เดิมมี 25 แถวแต่เมื่อเรา RUN แล้วเหลือ 23 แถว เท่านี้ก็เรียบร้อยแล้วค่ะ
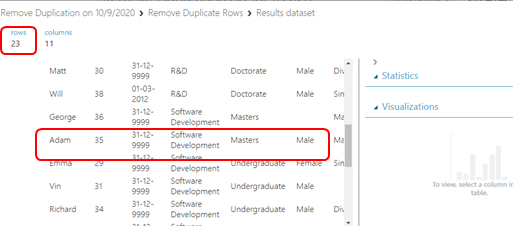
เมื่อเราทำตามขั้นตอนเหล่านี้ครบแล้วข้อมูลเราก็จะไม่มีแถวที่ซ้ำกันและพร้อมสำหรับกระบวนการถัดไปแล้วค่ะ
Fusion ให้บริการวิเคราห์และออกแบบระบบ Machine Learning ด้วยเครื่องมือ ของ
Microsoft Azure
02-440-0408 / sales@fusionsol.com
Link to Implement Azure , Implement Power BI