data mesh คือ
data mesh คือ สถาปัตยกรรมแพลตฟอร์มข้อมูลประเภทหนึ่ง ซึ่งแตกต่างจากโครงสร้างพื้นฐานข้อมูลแบบดั้งเดิมที่จัดการการบริโภคการจัดเก็บการแปลง และการส่งออกของข้อมูลใน data lake ส่วนกลาง data mesh เกี่ยวข้องกับการออกแบบที่ขับเคลื่อนด้วยโดเมน ซึ่งรวบรวมข้อมูลในองค์กรอย่างแพร่หลาย รองรับการกระจายข้อมูลเฉพาะโดเมน และมุมมอง “data-as-a-product” สำหรับแต่ละโดเมน จัดการท่อส่งข้อมูลของตนเอง เนื้อเยื่อที่เชื่อมต่อโดเมนเหล่านี้ และสินทรัพย์ข้อมูลที่เกี่ยวข้องเป็นเลเยอร์ความสามารถในการทำงานร่วมกันสากลที่ใช้ไวยากรณ์ และมาตรฐานข้อมูลเดียวกัน
Data mesh ประกอบด้วย
- Data product/ Service: ผู้ที่มีสถานะเป็นเจ้าของข้อมูลจะมีสิทธิ์ในการดูแลข้อมูลโดยตรง หากมีผู้ต้องการนำข้อมูลไปใช้ประโยชน์ จะสามารถเข้าถึงได้ด้วย API (Application Programming Interface – การเรียกใช้โปรแกรมแบบพูดคุยกันได้) ซึ่งในทางปฏิบัติ ข้อมูลอาจถูกเก็บไว้ใน cloud หรือ storage โดยให้หน่วยงานที่ต้องการนำข้อมูลไปใช้ เข้าถึงได้ด้วย URL แต่ไม่สามารถแก้ไขข้อมูล หรือ เป็นเจ้าของได้
- Discoverable data catalog: ต้องมีโครงสร้างพื้นฐานที่ช่วยทำให้การค้นหาข้อมูลภายในองค์กรมีประสิทธิภาพยิ่งขึ้น
- Self-serve platform: แพลตฟอร์มควรจะเอื้อประโยชน์ให้เจ้าของข้อมูลสามารถแชร์ข้อมูล และทำงานได้ง่าย สำหรับประเทศไทยอาจจะเพิ่มให้มีการบริหารจัดการ หรือ พัฒนา data product จากส่วนกลาง หากบางหน่วยงานไม่มีความสามารถที่จะทำได้ในเบื้องต้น
- Service Level; Objective (SLO) & Standardization: มีการกำหนดมาตรฐานข้อมูลและการให้บริการของข้อมูลที่ถูกต้องเชื่อถือได้ มีการจัดระเบียบข้อมูล (cleaning) และมีรายละเอียดอธิบายที่มาที่ไปของข้อมูล (Metadata) เพื่อให้ลูกค้าเข้าใจ และใช้งานได้อย่างเหมาะสม
- Global access control: ควรมีการกำหนดมาตรการการเข้าถึงข้อมูล และการดูแลความปลอดภัยของข้อมูล เพื่อสร้างความเชื่อมั่นให้กับผู้เป็นเจ้าของข้อมูลในการแชร์ข้อมูลที่เป็นประโยชน์สำหรับการนำไปใช้แก้โจทย์ให้กับองค์กรต่าง ๆ
หลักการทำงานของ Data mesh
การจัดการข้อมูลแบบ Big Data ในระบบ Distributed architecture แบ่ง product team ตาม data และแยกความซับซ้อนในการสร้าง product ให้ infrastructure team เป็นคนดูแล โดยประกอบไปด้วยหลักการ 4 ข้อ ดังนี้
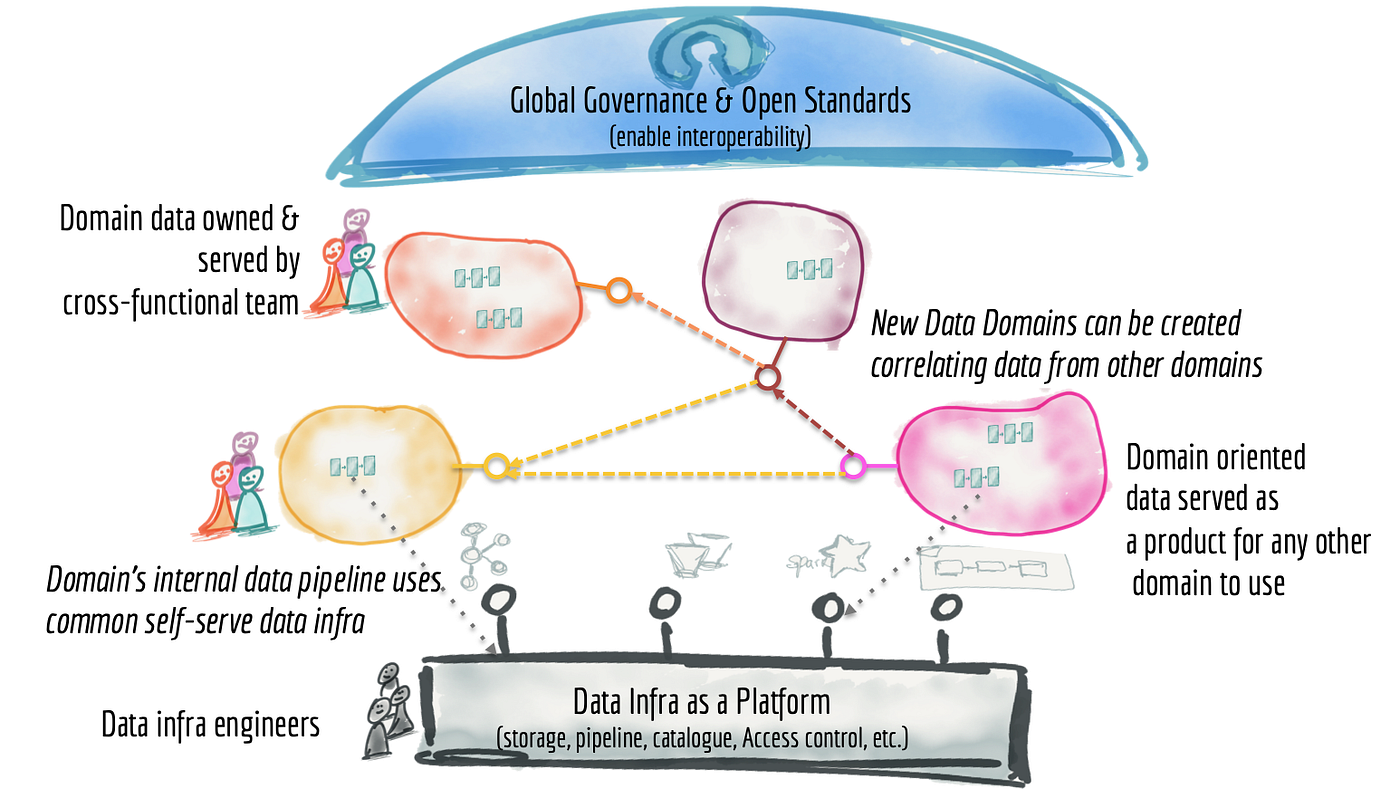
- Distributed architecture
– แบ่งการ ingest และ serve ตาม rate of change
– เก็บ data ส่วนของการ ingest เป็น event หรือ snapshot (immutable)
– เก็บ data ส่วนของการ serve เป็น historical data สำหรับการ replay - Product mindset
ที่เปลี่ยน mindset ของ organization structure จาก project เป็น product ทำให้เราจะได้ทีมที่มีทั้ง data engineer data scientist และ business analyst มาอยู่ด้วยกัน ส่งผลให้ทีมทำงานได้ดีขึ้น และแต่ละทีมจะมี input source และ output source ของตัวเอง - Self-serve
– Data provisioning engine (ช่วยสร้าง Data Lake หรือ Analytics platform ให้ product team)
– Data observability (monitoring, logging, alerting) - Governance
– Identity management อย่างการใช้งาน Customer data ก็ต้องนิยาม Customer ใน scope ของ ประกันชีวิต กับ ประกันภัย ให้่เป็นสิ่งเดียวกัน
– Deduplication (canonical data)





