ในยุคที่ขับเคลื่อนด้วยข้อมูล องค์กรต่าง ๆ สร้างและจัดการข้อมูลจำนวนมหาศาลในแต่ละวัน การบริหาร จัดเก็บ และวิเคราะห์ข้อมูลอย่างมีประสิทธิภาพกลายเป็น กลยุทธ์สำคัญ สำหรับธุรกิจ Data Lake คืออะไร? คำนี้หมายถึงสถาปัตยกรรมการจัดเก็บข้อมูลสมัยใหม่ที่ช่วยให้ธุรกิจสามารถ จัดเก็บข้อมูลขนาดใหญ่ได้หลากหลายประเภท ทั้งข้อมูลแบบมีโครงสร้าง กึ่งโครงสร้าง และไม่มีโครงสร้าง โดยไม่ต้องกำหนดรูปแบบล่วงหน้า
แตกต่างจาก คลังข้อมูลแบบดั้งเดิม (Data Warehouse) ที่ต้องกำหนดโครงสร้างของข้อมูลก่อนจัดเก็บ Data Lake มีความยืดหยุ่นสูง สามารถขยายขนาดได้ และรองรับการใช้งานสำหรับ Big Data Analytics, Machine Learning (ML), ปัญญาประดิษฐ์ (AI) และการประมวลผลข้อมูลแบบเรียลไทม์ แต่โครงสร้างนี้ทำงานอย่างไร? และเหตุใดองค์กรจำนวนมากจึงเริ่มใช้งานระบบนี้? มาดูรายละเอียดกัน
Data Lake คืออะไร และทำงานอย่างไร?
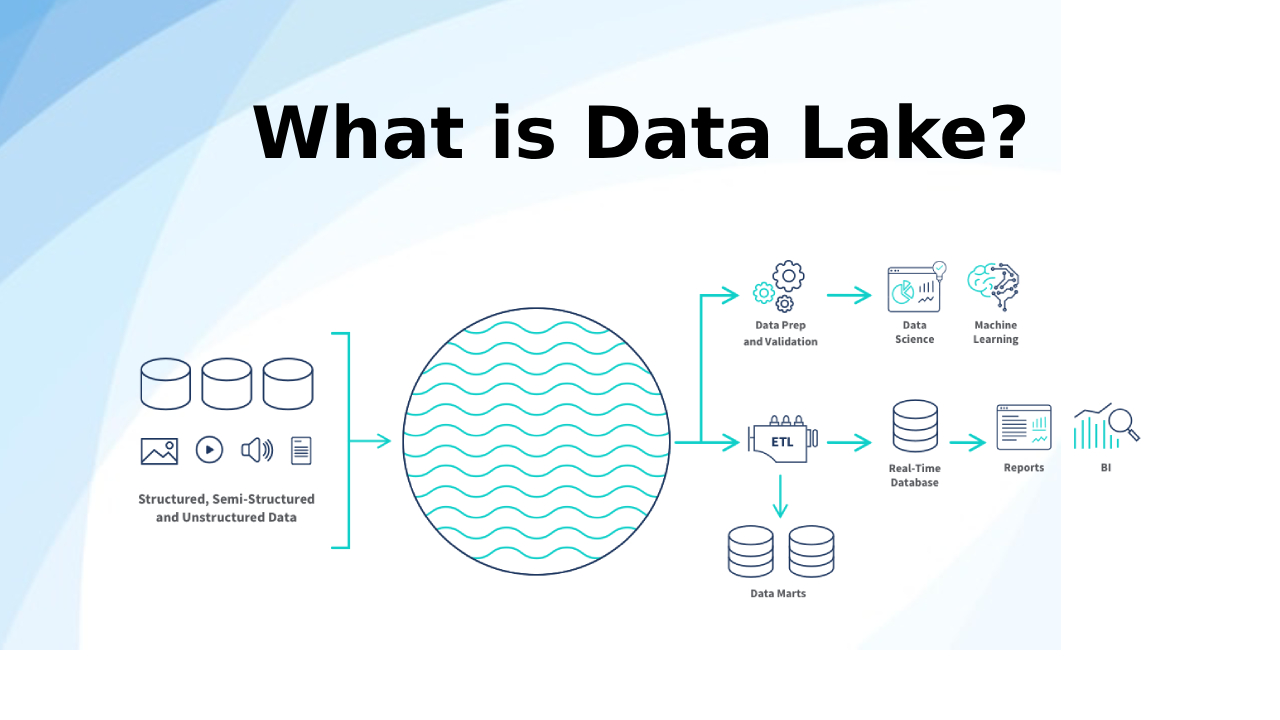
Data Lake เป็นระบบจัดเก็บข้อมูลที่สามารถ รวบรวม จัดเก็บ ประมวลผล และวิเคราะห์ข้อมูลจากแหล่งต่าง ๆ ได้อย่างยืดหยุ่น โดยไม่จำเป็นต้องแปลงข้อมูลให้เป็นรูปแบบเฉพาะก่อนการจัดเก็บ
องค์ประกอบหลักของ Data Lake
- Ingestion Layer – ทำหน้าที่ รวบรวมข้อมูลจากแหล่งต่าง ๆ เช่น ฐานข้อมูล IoT, API, ไฟล์ Log, โซเชียลมีเดีย และแอปพลิเคชันภายในองค์กร
- Storage Layer – ใช้สำหรับ จัดเก็บข้อมูลดิบ โดยไม่มีข้อจำกัดด้านรูปแบบ รองรับไฟล์ JSON, CSV, รูปภาพ, วิดีโอ และข้อมูลประเภทอื่น ๆ
- Processing Layer – ใช้ เทคโนโลยี Big Data เช่น Apache Spark และ Hadoop เพื่อวิเคราะห์และประมวลผลข้อมูล
- Consumption Layer – เชื่อมต่อกับ Business Intelligence (BI), Machine Learning และแพลตฟอร์มวิเคราะห์ข้อมูล เพื่อดึงข้อมูลมาใช้งาน
ด้วยสถาปัตยกรรมนี้ ธุรกิจสามารถ จัดเก็บข้อมูลขนาดใหญ่ได้อย่างคุ้มค่าและสามารถเรียกใช้งานได้เมื่อต้องการวิเคราะห์เชิงลึก
ข้อดีของการใช้ Data Lake

สำหรับองค์กรที่ต้องการใช้ประโยชน์จากข้อมูลขนาดใหญ่ Data Lake มีข้อได้เปรียบหลายประการ
- รองรับการจัดเก็บข้อมูลทุกรูปแบบโดยไม่ต้องแปลงล่วงหน้า
- รองรับ ข้อมูลที่มีโครงสร้าง (Structured), กึ่งโครงสร้าง (Semi-Structured) และไม่มีโครงสร้าง (Unstructured)
- ไม่ต้องกำหนดรูปแบบของข้อมูลก่อนจัดเก็บ ทำให้สามารถ จัดเก็บได้อย่างยืดหยุ่นและพร้อมนำไปวิเคราะห์ในภายหลัง
- ขยายขนาดได้ง่ายและต้นทุนต่ำ
- สามารถ ขยายพื้นที่จัดเก็บข้อมูลได้ตามความต้องการ รองรับ Big Data Storage ได้อย่างเต็มประสิทธิภาพ
- มีต้นทุนต่ำกว่าคลังข้อมูลแบบดั้งเดิม เพราะไม่ต้องเสียค่าใช้จ่ายในการจัดการโครงสร้างข้อมูล
- รองรับการวิเคราะห์ AI, Machine Learning และ Predictive Analytics
- เหมาะสำหรับ โมเดลปัญญาประดิษฐ์และการเรียนรู้ของเครื่อง ที่ต้องใช้ข้อมูลจำนวนมากในการฝึก
- รองรับ Deep Learning, Sentiment Analysis และระบบวิเคราะห์เชิงคาดการณ์ ได้อย่างแม่นยำ
- ประมวลผลข้อมูลแบบเรียลไทม์
- สามารถรวบรวม ข้อมูลสตรีมมิ่งจาก IoT, ธุรกรรมทางการเงิน และพฤติกรรมผู้ใช้ดิจิทัล
- เหมาะสำหรับการใช้งานที่ต้องการ การวิเคราะห์ข้อมูลแบบเรียลไทม์ เช่น การตรวจจับการฉ้อโกงและการคาดการณ์ตลาดหุ้น
- ผสานรวมกับเครื่องมือ BI และแพลตฟอร์มวิเคราะห์ข้อมูล
- รองรับ Power BI, Tableau, Google Looker และเครื่องมือวิเคราะห์ข้อมูลแบบกำหนดเอง
- ช่วยให้ธุรกิจสามารถ สร้างแดชบอร์ด วิเคราะห์แนวโน้ม และติดตามตัวชี้วัดทางธุรกิจ (KPI) ได้อย่างแม่นยำ
Data Lake vs. Data Warehouse: ความแตกต่างที่สำคัญ
หลายธุรกิจมักสับสนระหว่าง Data Lake และ Data Warehouse แต่ทั้งสองระบบนี้มีวัตถุประสงค์ในการใช้งานที่แตกต่างกัน:
คุณสมบัติ | Data Lake | Data Warehouse |
ประเภทข้อมูล | ข้อมูลดิบ, ไม่มีโครงสร้าง & มีโครงสร้าง | ข้อมูลที่ผ่านการประมวลผลและมีโครงสร้าง |
ข้อกำหนดโครงสร้างข้อมูล | Schema-on-read (จัดรูปแบบเมื่อต้องการใช้งาน) | Schema-on-write (ต้องกำหนดโครงสร้างก่อนจัดเก็บ) |
รูปแบบการประมวลผล | รองรับ AI, ML และการวิเคราะห์ข้อมูลขนาดใหญ่ | เหมาะสำหรับการสืบค้น SQL และการสร้างรายงาน |
กรณีการใช้งาน | การวิเคราะห์ขั้นสูง, การคาดการณ์แนวโน้ม | ธุรกิจที่ต้องการรายงานเชิงโครงสร้าง |
ประสิทธิภาพด้านต้นทุน | ต่ำกว่า (จัดเก็บข้อมูลดิบ) | สูงกว่า (ต้องใช้กระบวนการแปลงข้อมูลก่อนจัดเก็บ) |
Data Lake เหมาะสำหรับ การวิเคราะห์ข้อมูลแบบ AI, การจัดเก็บข้อมูลที่ไม่มีโครงสร้าง และการประมวลผลข้อมูลแบบเรียลไทม์ ในขณะที่ Data Warehouse เหมาะสำหรับ การสร้างรายงานทางธุรกิจที่มีโครงสร้างและระบบวิเคราะห์แบบดั้งเดิม
ความท้าทายทั่วไปและวิธีแก้ไข
แม้ว่า Data Lake จะมีข้อดีมากมาย แต่ก็มีความท้าทายบางประการที่องค์กรต้องเผชิญ
- การกำกับดูแลข้อมูลและความปลอดภัย
- ความท้าทาย: หากไม่มีการควบคุมที่เหมาะสม Data Lake อาจเสี่ยงต่อการละเมิดข้อมูล
- วิธีแก้ไข: ใช้ นโยบายควบคุมการเข้าถึง (Access Control), การเข้ารหัสข้อมูล และการปกปิดข้อมูล (Data Masking) เพื่อรักษาความปลอดภัยของข้อมูล
- ความเสี่ยงที่ Data Lake จะกลายเป็น “Data Swamp”
- ความท้าทาย: หากไม่มีการจัดระเบียบที่ดี ข้อมูลใน Data Lake อาจกระจัดกระจายและยากต่อการใช้งาน
- วิธีแก้ไข: ใช้ ระบบจัดการเมตาดาต้า (Metadata Management) และเครื่องมือจัดหมวดหมู่ข้อมูล (Data Cataloging) เพื่อช่วยติดตามและบริหารจัดการข้อมูล
- ปัญหาด้านประสิทธิภาพการทำงาน
- ความท้าทาย: การเรียกค้นข้อมูลดิบขนาดใหญ่อาจใช้เวลานานหากไม่มีการจัดการที่ดี
- วิธีแก้ไข: ใช้เทคนิค Data Partitioning, Indexing และ Caching เพื่อเพิ่มความเร็วในการประมวลผล
ด้วยการจัดการความท้าทายเหล่านี้อย่างเป็นระบบ องค์กรสามารถ เพิ่มประสิทธิภาพของ Data Lake ได้สูงสุด พร้อมรักษาความปลอดภัยและปฏิบัติตามข้อกำหนดด้านการจัดการข้อมูล
กรณีศึกษาการใช้งานจริงของ Data Lake
ธุรกิจค้าปลีกและอีคอมเมิร์ซ
- ติดตาม พฤติกรรมการซื้อและความชอบของลูกค้า
- ปรับปรุง การบริหารซัพพลายเชน ตามข้อมูลยอดขายแบบเรียลไทม์
ภาคการเงินและธนาคาร
- ตรวจจับ ธุรกรรมที่น่าสงสัย โดยใช้ AI เพื่อป้องกันการฉ้อโกง
- วิเคราะห์ โปรไฟล์ความเสี่ยงของลูกค้าและแนวโน้มการลงทุน
ภาคสาธารณสุขและเทคโนโลยีชีวภาพ
- วิเคราะห์ ข้อมูลจีโนมเพื่อการแพทย์เฉพาะบุคคล
- รองรับ AI-driven diagnostics และงานวิจัยทางการแพทย์
อุตสาหกรรม IoT และเทคโนโลยีอัจฉริยะ
- ประมวลผลข้อมูลแบบเรียลไทม์จาก รถยนต์ที่เชื่อมต่อและเซ็นเซอร์อุตสาหกรรม
- ช่วยพัฒนาระบบ บำรุงรักษาเชิงพยากรณ์และโครงสร้างพื้นฐานเมืองอัจฉริยะ
Data Lake ช่วยให้ธุรกิจในอุตสาหกรรมต่าง ๆ สามารถ แปลงข้อมูลดิบให้เป็นข้อมูลเชิงลึกที่นำไปใช้ได้จริง ช่วยเพิ่มประสิทธิภาพและขับเคลื่อนนวัตกรรม
วิธีเริ่มต้นใช้งาน Data Lake ในองค์กรของคุณ
หากต้องการติดตั้งและใช้งาน Data Lake อย่างมีประสิทธิภาพ ธุรกิจควรดำเนินการตามขั้นตอนต่อไปนี้:
- ประเมินความต้องการด้านข้อมูล – ระบุ แหล่งข้อมูล ปริมาณ และประเภทของข้อมูล เพื่อตั้งค่าระบบจัดเก็บที่เหมาะสม
- เลือกแพลตฟอร์มคลาวด์ – Microsoft Azure, AWS และ Google Cloud มีโซลูชัน Data Lake ที่สามารถบริหารจัดการได้ง่าย
- กำหนดนโยบายการกำกับดูแลข้อมูล – ใช้ Role-Based Access Control (RBAC) และการเข้ารหัสข้อมูล เพื่อรักษาความปลอดภัย
- ผสานรวมเครื่องมือประมวลผลข้อมูล – ใช้ Big Data Frameworks เช่น Apache Spark และ Hadoop สำหรับการวิเคราะห์ข้อมูลขั้นสูง
- ติดตามและปรับปรุงประสิทธิภาพ – ใช้ เครื่องมือตรวจสอบเมตาดาต้า การทำดัชนี และการปรับปรุงประสิทธิภาพของ Query
การดำเนินการตามขั้นตอนเหล่านี้จะช่วยให้ธุรกิจสามารถ สร้าง Data Lake ที่ปลอดภัย มีโครงสร้างที่ดี และมีประสิทธิภาพสูง
สรุป : Data Lake คืออะไร?
สำหรับธุรกิจที่ต้องการโซลูชัน การจัดเก็บข้อมูลที่ยืดหยุ่น ขยายขนาดได้ และมีต้นทุนต่ำ Data Lake เป็นตัวเลือกที่ยอดเยี่ยม ด้วยความสามารถในการ จัดเก็บข้อมูลดิบและรองรับการวิเคราะห์ขั้นสูง องค์กรสามารถ ปลดล็อกศักยภาพของข้อมูลขนาดใหญ่ ได้อย่างมีประสิทธิภาพ
Data Lake คืออะไร? กล่าวโดยสรุป มันคือคลังข้อมูลยุคใหม่ที่ออกแบบมาเพื่อจัดเก็บและประมวลผลข้อมูลปริมาณมหาศาลได้อย่างมีประสิทธิภาพ บริษัทที่ต้องการ พัฒนาการวิเคราะห์แบบเรียลไทม์ ฝึกโมเดล AI และขับเคลื่อนการตัดสินใจด้วยข้อมูล ควรพิจารณานำเทคโนโลยีนี้ไปใช้
หากต้องการศึกษาข้อมูลเพิ่มเติมเกี่ยวกับแนวทางการใช้งานและประโยชน์ของระบบจัดเก็บข้อมูลรูปแบบนี้ สามารถดูรายละเอียดได้ที่ Microsoft Azure Data Lake เพื่อสำรวจโซลูชันที่เหมาะสมสำหรับธุรกิจของคุณ.
สำรวจเครื่องมือดิจิทัลของเรา
หากคุณสนใจในการนำระบบจัดการความรู้มาใช้ในองค์กรของคุณ ติดต่อ SeedKM เพื่อขอข้อมูลเพิ่มเติมเกี่ยวกับระบบจัดการความรู้ภายในองค์กร หรือสำรวจผลิตภัณฑ์อื่นๆ เช่น Jarviz สำหรับการบันทึกเวลาทำงานออนไลน์, OPTIMISTIC สำหรับการจัดการบุคลากร HRM-Payroll, Veracity สำหรับการเซ็นเอกสารดิจิทัล, และ CloudAccount สำหรับการบัญชีออนไลน์
อ่านบทความเพิ่มเติมเกี่ยวกับระบบจัดการความรู้และเครื่องมือการจัดการอื่นๆ ได้ที่ Fusionsol Blog, IP Phone Blog, Chat Framework Blog, และ OpenAI Blog.




