
ในยุคที่ AI ถูกใช้งานในทุกภาคส่วน ตั้งแต่การตอบแชทไปจนถึงการเขียนโค้ดหรือค้นหาข้อมูล เราจำเป็นต้องมีเครื่องมือที่แม่นยำในการวัด “ความฉลาด” และ “ความเข้าใจโลกจริง” ของ AI อย่างแท้จริง และนั่นคือเหตุผลที่ OpenAI ได้เปิดตัว BrowseComp ซึ่งเป็น benchmark for AI agents รูปแบบใหม่ที่เน้นการทดสอบการคิดวิเคราะห์และการค้นหาข้อมูลบนโลกอินเทอร์เน็ตที่ซับซ้อน
Benchmark for AI Agents คืออะไร?
Benchmark คือมาตรฐานหรือชุดการทดสอบที่ใช้วัดประสิทธิภาพของโมเดล AI ส่วน benchmark for AI agents อย่าง BrowseComp คือชุดคำถามที่ไม่ได้เน้นแค่ความรู้ทั่วไปหรือคำตอบตรงๆ แต่ทดสอบว่า agent หรือโมเดล AI สามารถ:
- ค้นหาข้อมูลจากเว็บในเวลาจำกัด
- วิเคราะห์ข้อมูลที่มีความกำกวม
- ตัดสินใจระหว่างข้อมูลที่ขัดแย้งกัน
- นำเสนอคำตอบอย่างมีเหตุผลและอ้างอิง
BrowseComp มีอะไรพิเศษ?
BrowseComp ประกอบด้วยคำถามที่เรียกว่า “search-intensive questions” จำนวน 1,266 ข้อ โดยคำถามเหล่านี้มีคุณสมบัติดังนี้:
ต้องค้นหาเชิงลึก (Deep Search)
คำถามไม่ได้สามารถตอบจากแหล่งเดียว แต่ต้องรวมข้อมูลจากหลายเว็บไซต์ เช่น:
“ใครคือผู้แต่งชีวประวัติของนักเขียนนิยายที่ใช้นามปากกาและมีความเกี่ยวข้องกับเหตุการณ์ในปี 1980?”
ต้องวิเคราะห์เชิงเหตุผล
AI ต้องใช้ reasoning เพื่อสรุปคำตอบ เช่น:
- ใครเขียน? ใช้นามปากกาไหน?
- เหตุการณ์ปีไหน? ในบริบทอะไร?
- เว็บไซต์ไหนเชื่อถือได้?
ต้องใช้เว็บอย่างมีประสิทธิภาพ
Agent ต้องสามารถใช้งานเว็บอย่างชาญฉลาด เช่น:
- เลือกใช้ Search Engine
- เข้าเว็บไซต์ได้เหมาะสม
- อ่านเนื้อหาจากหลายแหล่ง และประเมินความถูกต้อง
ความหลากหลายและความยากของชุดข้อมูล
ในการสร้างชุดทดสอบ BrowseComp เราสนับสนุนให้ผู้ฝึกสอนสร้างคำถามเกี่ยวกับหัวข้อที่ตนเองสนใจเป็นการส่วนตัว โดยหวังว่าการสร้างคำถามจากความสนใจส่วนตัวจะทำให้ประสบการณ์ในการฝึกอบรมสนุกยิ่งขึ้นและส่งผลให้ได้ข้อมูลที่มีคุณภาพสูงขึ้น รูปแบบการกระจายของหัวข้อคำถามสามารถดูได้จากแผนภูมิวงกลมด้านล่าง
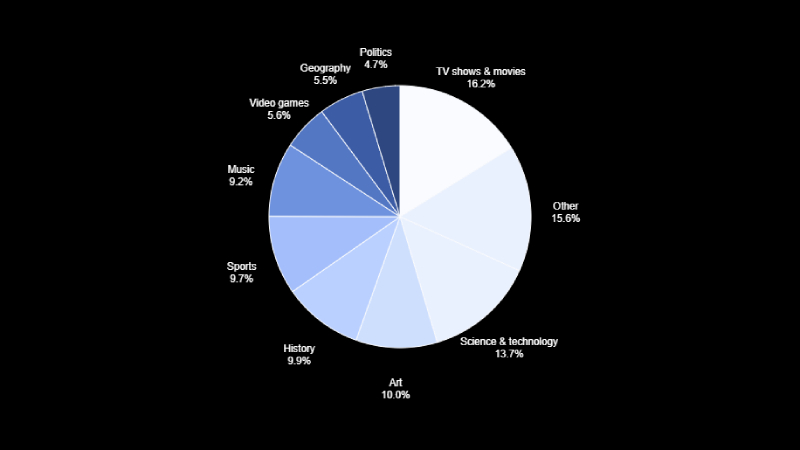
เพื่อเป็นหนึ่งในตัวชี้วัดว่าชุดข้อมูล BrowseComp นั้นท้าทายเพียงใด เราได้ขอให้ผู้ฝึกสอนทดลองตอบคำถามใน BrowseComp ด้วยเช่นกัน ผู้ฝึกสอนเหล่านี้เป็นกลุ่มเดียวกับที่ใช้สร้างคำถาม แต่จะไม่ได้รับอนุญาตให้ตอบคำถามที่ตนเองเป็นผู้สร้างขึ้น และจะไม่สามารถเข้าถึงคำตอบที่ถูกต้องได้ อีกทั้งต้องทำภารกิจโดยไม่ใช้ผู้ช่วย AI (โดยเฉพาะอย่างยิ่งห้ามใช้ ChatGPT, Claude, Perplexity, Grok หรือ Gemini)
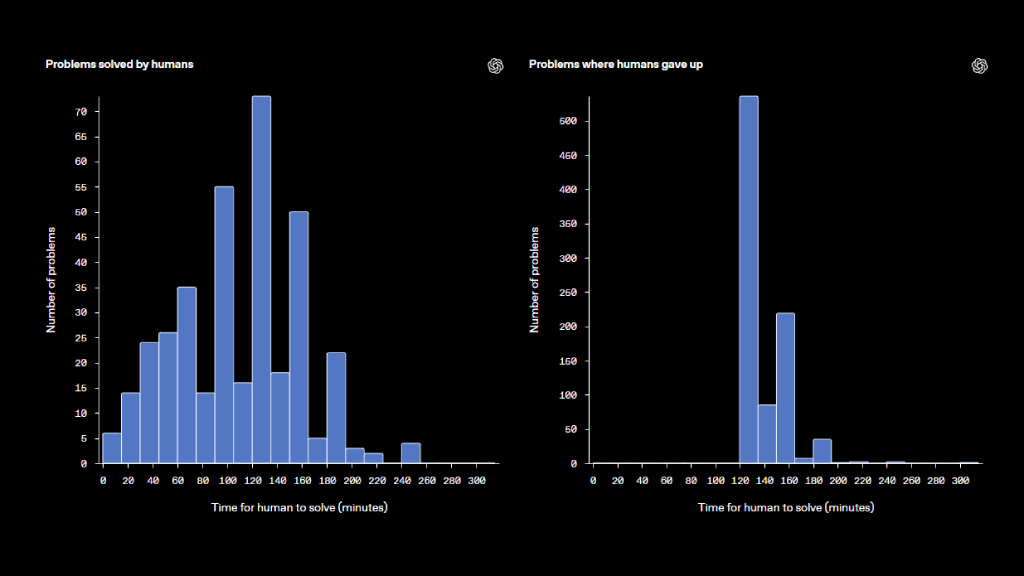
เนื่องจากคำถามบางข้อยากมาก เราจึงอนุญาตให้ผู้ฝึกสอนระบุว่าคำถามนั้น “ไม่สามารถตอบได้” และข้ามไปได้ หากไม่สามารถหาคำตอบได้ภายในเวลาสองชั่วโมง จากผลลัพธ์ที่แสดงด้านล่าง ผู้ฝึกสอนสามารถตอบคำถามได้ 29.2% ของคำถามทั้งหมด และในกลุ่มคำถามที่ตอบได้ คำตอบจากผู้ฝึกสอนตรงกับคำตอบอ้างอิงเดิมถึง 86.4%
หมวดหมู่ | ค่า |
จำนวนปัญหาทั้งหมดในการตรวจสอบความถูกต้อง | 1,255 |
ไม่สามารถแก้ไขได้ | 888 / 1,255 (70.8%) |
สามารถแก้ไขได้ | 367 / 1,255 (29.2%) |
คำตอบของผู้ฝึกสอนตรงกับคำตอบอ้างอิง (เฉพาะปัญหาที่แก้ได้) | 317 / 367 (86.4%) |
ผู้ฝึกสอนรายงานด้วยตนเองว่าใช้เวลาเท่าใดในการตอบคำถามแต่ละข้อ แผนภูมิแท่งด้านล่างแสดงการกระจายของระยะเวลาในการตอบคำถามสำหรับทั้งคำถามที่ตอบได้และไม่ได้ สำหรับคำถามที่มนุษย์สามารถตอบได้ เราจะเห็นช่วงเวลาที่หลากหลาย — บางคำถามใช้เวลาค้นหาน้อยกว่าหนึ่งชั่วโมง ขณะที่อีกหลายคำถามต้องใช้เวลาค้นหาสองถึงสามชั่วโมงกว่าจะได้คำตอบ สำหรับคำถามที่ไม่สามารถตอบได้ ผู้ฝึกสอนส่วนใหญ่มักตัดสินใจยอมแพ้หลังจากพยายามค้นหาคำตอบเป็นเวลาประมาณสองชั่วโมง
ใครบ้างที่สามารถใช้ BrowseComp?
BrowseComp ถูกออกแบบให้เหมาะสำหรับ:
กลุ่มผู้ใช้ | ประโยชน์ที่ได้รับ |
นักวิจัยด้าน AI | ใช้วัดและเปรียบเทียบประสิทธิภาพของโมเดล browsing agents |
นักพัฒนา AI Agent | ใช้เพื่อเทรนหรือ fine-tune agent ให้เก่งขึ้นในโลกความจริง |
ผู้ใช้ทั่วไปหรือองค์กร | ประเมินได้ว่า agent ตัวใดน่าเชื่อถือ และใช้ได้จริงในเชิงการค้นหาข้อมูลบนเว็บ |
จุดเด่นของ BrowseComp เมื่อเทียบกับ benchmark อื่น
ประเภท Benchmark | รายละเอียด |
MMLU / TriviaQA | ทดสอบความรู้ทั่วไปจากคลังข้อมูลเดิม ไม่ต้องค้นหาแบบ real-time |
ARC / GSM8K | ทดสอบตรรกะและคณิตศาสตร์ แต่ไม่ได้ใช้ข้อมูลจากเว็บ |
BrowseComp | ทดสอบการ “ใช้งานเว็บ” เพื่อแก้ปัญหาซับซ้อน ต้องวิเคราะห์หลายชั้น |
BrowseComp จึงเติมเต็มช่องว่างที่ benchmark รุ่นเก่าไม่สามารถวัดได้ — นั่นคือ “ความสามารถในการใช้เว็บอย่างมีเหตุผล”
BrowseComp กับการพัฒนา AI Agents ในอนาคต
OpenAI เชื่อว่าในอนาคต AI จะไม่ใช่เพียงแค่ระบบที่ “รู้ทุกอย่าง” แต่ต้องเป็นผู้ช่วยที่ “ค้นหา วิเคราะห์ และตัดสินใจอย่างเข้าใจบริบท” BrowseComp จึงกลายเป็น:
- ตัวชี้วัดสำหรับโมเดลใหม่ๆ เช่น GPT-4 with Browsing หรือ Agents ที่ใช้ Search API
- จุดเริ่มต้นของการแข่งขันและพัฒนา agent แบบ open-source เช่น AutoGPT, WebGPT, หรือ LangChain Agent
นอกจากนี้ BrowseComp ยังถูกออกแบบให้:
- ใช้งานได้ฟรีและเป็น Open Dataset
- รองรับการประเมินผลแบบอัตโนมัติ
- สนับสนุนการใช้งานในงานวิจัยระดับมหาวิทยาลัย
ข้อมูลทางเทคนิค (Technical Summary)
- จำนวนคำถาม: 1,266
- รูปแบบคำถาม: Free-form, Open-ended
- แหล่งข้อมูลเป้าหมาย: Real-time Web
- การให้คะแนน: Human-labeled และ Automatic evaluation
- ภาษา: ภาษาอังกฤษทั้งหมด
- ลิงก์ GitHub: BrowseComp GitHub
สรุป
BrowseComp คือ benchmark for AI agents ที่ทันสมัยที่สุดในยุคนี้ เพราะมันไม่ใช่แค่การทดสอบความรู้ที่ฝังอยู่ในโมเดล แต่เป็นการวัด “ทักษะการค้นหา วิเคราะห์ และกลั่นกรองข้อมูลจากโลกออนไลน์จริง” หากคุณต้องการสร้าง agent ที่เข้าใจโลกและทำงานแทนมนุษย์ได้อย่างมีประสิทธิภาพ BrowseComp คือบททดสอบที่คุณควรลอง
อ่านฉบับเต็มจาก OpenAI ได้ที่ BrowseComp Overview
สนใจผลิตภัณฑ์และบริการของ Microsoft หรือไม่ ส่งข้อความถึงเราที่นี่
สำรวจเครื่องมือดิจิทัลของเรา
หากคุณสนใจในการนำระบบจัดการความรู้มาใช้ในองค์กรของคุณ ติดต่อ SeedKM เพื่อขอข้อมูลเพิ่มเติมเกี่ยวกับระบบจัดการความรู้ภายในองค์กร หรือสำรวจผลิตภัณฑ์อื่นๆ เช่น Jarviz สำหรับการบันทึกเวลาทำงานออนไลน์, OPTIMISTIC สำหรับการจัดการบุคลากร HRM-Payroll, Veracity สำหรับการเซ็นเอกสารดิจิทัล, และ CloudAccount สำหรับการบัญชีออนไลน์
อ่านบทความเพิ่มเติมเกี่ยวกับระบบจัดการความรู้และเครื่องมือการจัดการอื่นๆ ได้ที่ Fusionsol Blog, IP Phone Blog, Chat Framework Blog, และ OpenAI Blog.
Cyborg cockroaches เทคโนโลยีกู้ภัยสุดล้ำ
ถ้าอยากติดตามข่าวเทคโนโลยีและข่าว AI ที่กำลังเป็นกระแสทุกวัน ลองเข้าไปดูที่ เว็บไซต์นี้ มีอัปเดตใหม่ๆ ให้ตามทุกวันเลย!
ทำไม มีส่วนร่วมทันที Chatbots เป็นกุญแจสำคัญในการยกระดับประสบการณ์ผู้ใช้ของคุณ




