จุดเริ่มต้นของความสำเร็จ ChatGPT
เมื่อปลายปีที่แล้ว มีการปล่อยตัว แชทบอท ออกมาเรียกเสียงฮือฮา สะเทือนวงการเทคโนโลยี และกลายเป็นกระแสไวรัลอย่างรวดเร็ว นั่นก็คือ ChatGPT
ChatGPT รูปแบบหนึ่งของ GPT-3.5 ถูกพัฒนามาจาก GPT (Generative Pre-training Transformer) language model โดย OpenAI ได้รับการออกแบบมาโดยเฉพาะสำหรับแอปพลิเคชันแชทบอท ทำให้สามารถสร้างการตอบสนองที่เหมือนมนุษย์ต่อการป้อนข้อมูลของผู้ใช้แบบเรียลไทม์ ซึ่งนอกจากความสามารถด้านการสนทนาแล้ว ChatGPT ยังสามารถทำงานด้านการประมวลผลภาษาธรรมชาติอื่น ๆ ได้อีกหลากหลาย เช่น การแปล การสรุป และการวิเคราะห์ความรู้สึก
ในบทความนี้ เราจะมาพูดถึง Generative Pre-training Transformer หรือ GPT ซึ่งเป็นหนึ่งในโมเดลพื้นฐานที่สำคัญที่สุดในการทำความเข้าใจภาษา
ก่อนอื่นขอพูดถึง Language model เพื่อให้เข้าใจได้ง่ายขึ้นก่อน Language model เป็นงานการประมวลผลภาษาธรรมชาติ (Natural language processing: NLP) ที่ใช้ศาสตร์ของสถิติ และความน่าจะเป็นในการหาลำดับคำที่เกิดขึ้นในประโยค โดยวิเคราะห์จากเนื้อความของบริบทเพื่อการทำนายคำถัดไป โดยงานหลักของ NLP เป็นไปตามรูปแบบของ self-supervised pre-training a corpus on the language model architecture ตามด้วยการทำ fine-tuning ในแต่ละงานเฉพาะ
Generative Pre-training Transformer คือ language generation model ที่พัฒนาโดย OpenAI ซึ่ง GPT-3 เป็นรุ่นที่ 3 ของ GPT series ที่ถูกปล่อยออกมาอย่างเป็นทางการ
ตระกูลของโมเดลของ GPT มีความแตกต่างกันในด้านของความจุ และราคา อีกทั้งเรายังสามารถที่จะปรับแต่งโมเดลพื้นฐานสำหรับการใช้งานในกรณีเฉพาะด้านด้วย fine-tuning อีกด้วย อย่างที่ได้กล่าวไว้ในตอนแรกว่าโมเดล GPT-3 มีความสามารถในการทำความเข้าใจ และสร้างภาษาธรรมชาติได้ โดยหลัก ๆ จะมีอยู่ 4 รุ่น ที่แตกต่างกัน เหมาะสำหรับงานที่แตกต่างกัน เรามาดูกันว่า 4 รุ่นนี้มีอะไรบ้าง
- Davinci
Davinci เป็นโมเดลที่มีความสามารถมากที่สุดในตระกูลนี้ สามารถทำบางงานที่โมเดลอื่น ๆ ก็ทำได้ สำหรับแอปพลิเคชันที่ต้องการความเข้าใจเนื้อหาอย่างมาก เช่น การสรุปสำหรับผู้ชมเฉพาะกลุ่ม และการสร้างเนื้อหาที่สร้างสรรค์ Davinci จะให้ผลลัพธ์ที่ดีที่สุด แต่การที่ Davinci มีความสามารถที่ดีขึ้นแปลว่าจะต้องมีทรัพยากรการประมวลผลมากขึ้นด้วย ดังนั้น Davinci จึงมีค่าใช้จ่ายมากขึ้นต่อการเรียกใช้ API หนึ่งครั้ง และไม่เร็วเท่ากับรุ่นอื่น ๆ
ใช้งานได้ดี : Complex intent, cause and effect, summarization for audience
โมเดลที่ถูกปล่อยมาล่าสุด : text-davinci-003
- Curie
Curie มีพลังงานมาก และยังมีความเร็วมากด้วย ขณะที่ Davinci มีความสามารถมากกว่าในการวิเคราะห์ข้อความที่ซับซ้อน แต่ Curie จะค่อนข้างมีความสามารถสำหรับงานที่แตกต่างกันเล็กน้อย เช่น การจำแนกความรู้สึก และการสรุป Curie ค่อนข้างใช้งานได้ดีในการตอบคำถาม และดำเนินการ Q & A เป็น chatbot บริการทั่วไป
ใช้งานได้ดี : Language translation, complex classification, text sentiment, summarization
โมเดลที่ถูกปล่อยมาล่าสุด : text-curie-001
- Babbage
Babbage สามารถทำงานที่มีความตรงไปตรงมา เช่น การจัดหมวดหมู่อย่างง่าย นอกจากนี้ยังมีความสามารถในการจัดลำดับ Semantic Search ว่าเอกสารตรงกับข้อความค้นหาได้ดีเพียงใด
ใช้งานได้ดี : Moderate classification, semantic search classification
โมเดลที่ถูกปล่อยมาล่าสุด : text-babbage-001
- Ada
โดยปกติแล้ว Ada จะเป็นโมเดลที่เร็วที่สุด และสามารถทำงานต่าง ๆ เช่น การแยกวิเคราะห์ข้อความ การแก้ไขที่อยู่ และงานจัดประเภทบางประเภทที่ไม่ต้องการความแตกต่างเล็กน้อยมากนัก ประสิทธิภาพของ Ada สามารถปรับปรุงได้โดยการให้บริบทเพิ่มเติม
ใช้งานได้ดี : Parsing text, simple classification, address correction, keywords
โมเดลที่ถูกปล่อยมาล่าสุด : text-ada-001
อ้างอิง https://beta.openai.com/docs/models
Fine-tuning วิธีการปรับแต่งโมเดลให้เหมาะสมกับการใช้งาน
ต่อเนื่องจากบทความก่อนหน้านี้ ที่เราได้พูดถึง GPT-3 และการเกริ่นถึง Fine-tuning บ้างแล้ว บทความนี้เราจะมาเน้นที่การทำ Fine-tuning กันบ้าง
Fine-tuning คือกระบวนการฝึกโมเดลภาษา เพื่อจดจำรูปแบบการข้อมูลนำเข้า และผลลัพธ์โดยเฉพาะ ซึ่งสามารถนำไปใช้กับงาน NLP ที่กำหนดเองใด ๆ ก็ได้ โดยที่เราต้องใส่ดข้อมูลที่กำหนดเองของเราลงไป เพื่อให้โมเดลสามารถสรุปผลลัพธ์ให้เหมาะสมกับงานเฉพาะของเราได้
GPT-3 ได้รับการฝึกฝนล่วงหน้าด้วยข้อความจำนวนมากจากอินเทอร์เน็ต GPT-3 สามารถทำความเข้าใจว่างานใดที่กำลังพยายามทำอยู่ และทำให้เกิดผลสำเร็จ แม้จะได้รับ prompt เพียงเล็กน้อย นั่นคือ “few-shot learning”
โดยขั้นตอนของการทำ Fine-tuning มีดังนี้
- การเตรียมข้อมูล และอัปโหลดข้อมูลการฝึกฝน
สำหรับข้อมูลในการฝึกสอนนั้น จำเป็นต้องเป็นไฟล์ JSONL โดยที่แต่ละบรรทัดจะเป็นคู่ของ prompt-completion ดังตัวอย่างข้างล่าง
{“prompt”: “<prompt text>”, “completion”: “<ideal generated text>”}
{“prompt”: “<prompt text>”, “completion”: “<ideal generated text>”}
{“prompt”: “<prompt text>”, “completion”: “<ideal generated text>”}
…
เราสามารถใช้ CLI data preparation tool เครื่องมือสำหรับการเตรียมข้อมูลที่จะทำให้สะดวกสบายในการแปลงข้อมูลของเราให้อยู่ในรูปแบบไฟล์ JSONL
การออกแบบ prompt และ completion สำหรับ fine-tuning นั้นจะแตกต่างกับ prompt ที่ใช้กับโมเดลพื้นฐาน (Davinci, Curie, Babbage และ Ada) ตัวอย่างการฝึกแต่ละตัวอย่าง โดยทั่วไปจะประกอบด้วยตัวอย่างอินพุตเดียว และเอาต์พุตที่เกี่ยวข้อง โดยไม่จำเป็นต้องให้คำแนะนำโดยละเอียด หรือรวมหลายตัวอย่างไว้ใน prompt เดียวกัน
Data formatting
สำหรับการทำ fine-tuning จำเป็นจะต้องมีชุดข้อมูลตัวอย่างในการฝึก ซึ่งแต่ละชุดจะประกอบด้วย single input (“prompt”) และ associated output (“completion”) โดยมีข้อกำหนดดังนี้
- แต่ละ prompt ควรลงท้ายด้วยตัวคั่นคงที่ เพื่อทำให้โมเดลรู้ว่า prompt สิ้นสุดจุดไหน ตัวคั่นอย่างง่ายที่ใช้โดยทั่วไปคือ \n\n###\n\n และที่สำคัญตัวคั่นไม่ควรปรากฏที่อื่นใน prompt ใด ๆ
- แต่ละ completion ควรเริ่มต้นด้วยเว้นวรรค และควรจบด้วยตัวคั่นคงที่อาจเป็น \n, ### หรืออื่น ๆ
CLI data preparation tool
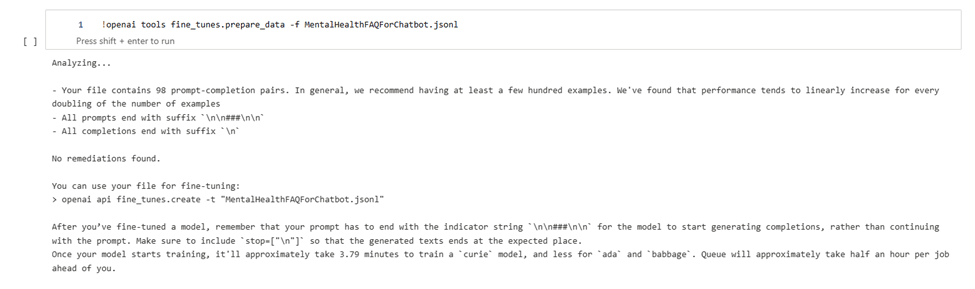
เครื่องมือนี้ช่วยในการเตรียมข้อมูล โดยมีข้อกำหนด คือต้องมี prompt และ completion เราสามารถส่งไฟล์ CSV, TSV, XLSX, JSON หรือ JSONL ได้เลย และจะได้ผลลัพธ์เป็นไฟล์ JSONL ที่พร้อมสำหรับ fine-tuning โดยใช้คำสั่ง
openai tools fine_tunes.prepare_data -f <LOCAL_FILE>
- สร้างโมเดล fine-tuned
หลังจากที่ทำการเตรียมข้อมูลเรียบร้อยแล้ว แต่ก่อนจะสร้าง fine tune model จำเป็นจะต้องมี OPENAI API KEY ก่อน

เราจะใช้ OpenAI CLI:
openai api fine_tunes.create -t <TRAIN_FILE_ID_OR_PATH> -m <BASE_MODEL>
โดยที่ BASE_MODEL คือชื่อของโมเดลพื้นฐานเริ่มต้น (ada, babbage, curie หรือ davinci) และเราสามารถปรับแต่งชื่อโมเดล fine-tuned ได้โดยใช้ suffix parameter
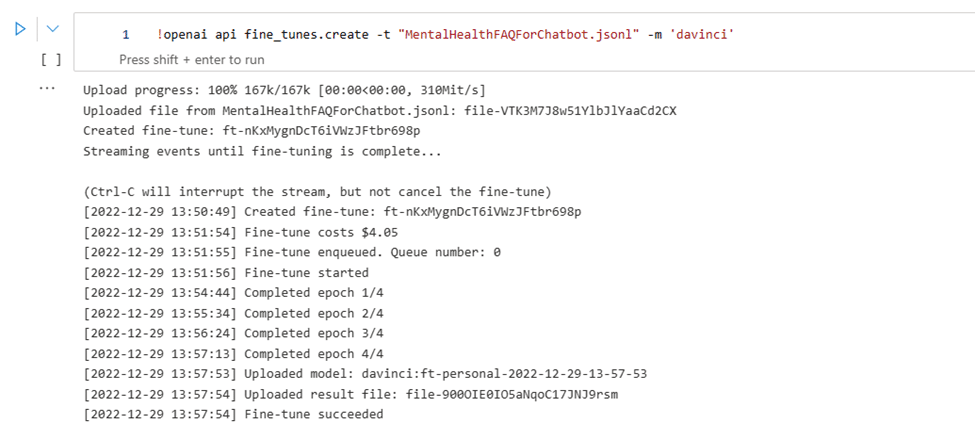
งาน fine-tuning ทุกอย่างเริ่มต้นจากโมเดลพื้นฐาน ซึ่งมีค่าเริ่มต้นเป็น Curie การเลือกโมเดลจะส่งผลต่อทั้งประสิทธิภาพ และราคาในการรันโมเดล fine-tuned หลังจากที่คุณเริ่มงาน fine-tune อาจต้องใช้เวลาสักระยะจึงจะเสร็จสมบูรณ์ ขึ้นอยู่กับโมเดลและขนาดชุดข้อมูล ซึ่งหากเปิดเหตุการณ์การรันถูกขัดจังหวะ เราสามารถดำเนินการต่อได้โดยเรียกใช้
openai api fine_tunes.follow -i <YOUR_FINE_TUNE_JOB_ID>
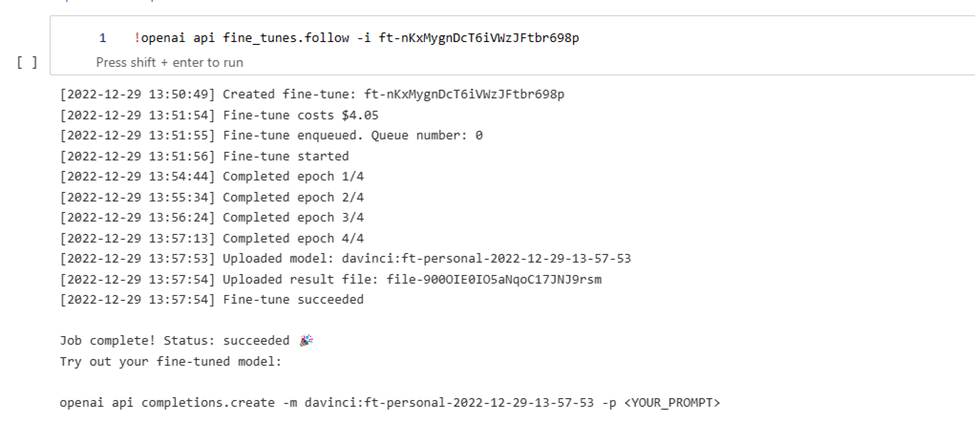
- ใช้งานโมเดล fine-tuned
เมื่อขั้นตอนที่ 2 สำเร็จ โมเดล Fine tuned ที่เราสร้างจะไปปรากฏในช่อง model ของ playground เราสามารถระบุโมเดลนี้เป็นพารามิเตอร์ของ API
Reference : ChatGPT Fusion
Chat GPT Service by Fusion
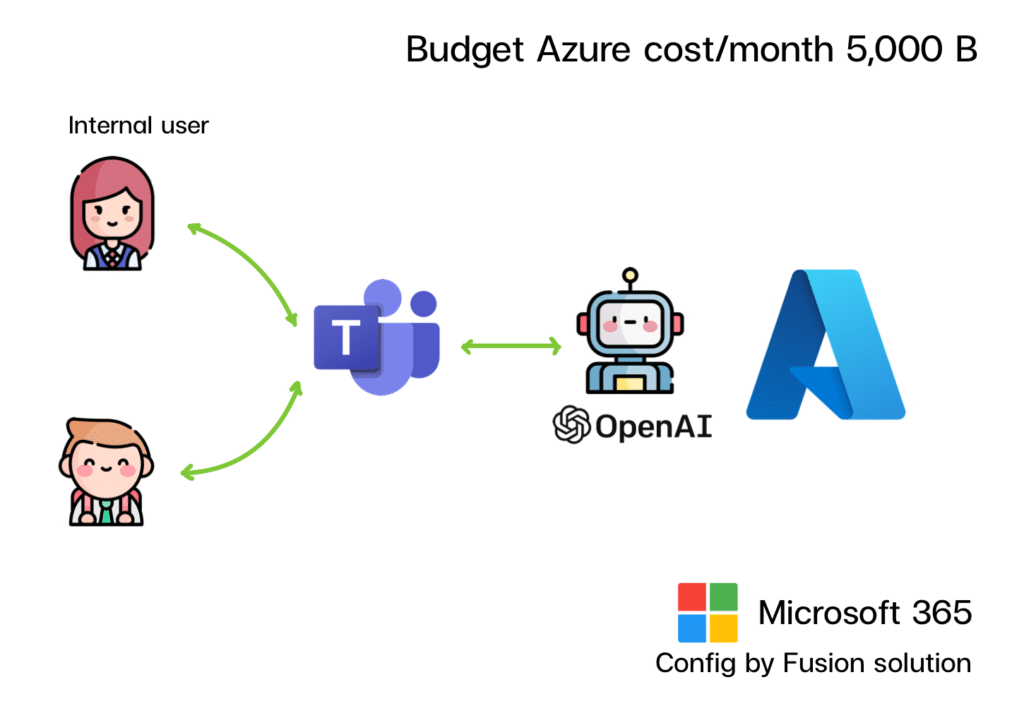
ใช้ ChatGPT ในองค์กร ผ่าน MS Team Fusion มีบริการ Config GPT สำหรับใช้ภายในองค์กร ภายใต้ Azure Service มั่นใจได้ 100 % ว่าข้อมูลที่คุยกับระบบ GPT จะไม่ถูกนำออกไปใช้ภายนอกบริษัท
รายละเอียดการให้บริการ
- เปิด Service Cognitive Service ( OpenAI 4.0)
- Connect MS Team
- Short memory
- Security Config
- log history เก็บข้อมูลการคุยในรูปแบบ Database
ใช้เวลา Config หลังจากเปิด Service เรียบร้อยภายใน 2 วัน สามารถควบคุมงบประมาณได้ 100 %
Security Detail https://learn.microsoft.com/…/cogni…/openai/data-privacy