The next evolution in AI-assisted software development has arrived. GPT-5.3 Codex Spark is now available as a research preview—introducing OpenAI’s first model specifically designed for real-time coding collaboration.
As an ultra-small and fast model built upon the GPT-5.3 Codex, GPT-5.3 Codex Spark is optimized for near-instantaneous responsiveness. Served via ultra-low latency hardware in collaboration with Cerebras, the model can generate over 1000 tokens per second, elevating the fluidity of AI software development to a new level.
What is GPT-5.3 Codex Spark?
The GPT-5.3 Codex Spark is a high-speed coding model designed to support:
- Interactive development
- Rapid iteration
- Immediate logic refinement
- Near-instant code edits
Unlike larger frontier models designed for long-running autonomous tasks that span hours or days, GPT-5.3 Codex Spark is optimized for working in the moment. It allows developers to reshape logic, adjust structure, or refine interfaces and see results instantly.
It currently supports:
- 128K context window
- Text-only inputs
- Separate research preview rate limits
- Access for ChatGPT Pro users
Importantly, usage during the research preview does not count toward standard rate limits.
Designed for Real-Time Collaboration
Speed matters in software development. GPT-5.3 Codex Spark is built for interactive collaboration where latency is just as important as intelligence.
Developers can:
- Interrupt and redirect the model mid-task
- Iterate rapidly with near-instant responses
- Make precise, minimal code edits
- Avoid automatic test execution unless requested
The model defaults to a lightweight working style. Instead of over-engineering solutions, GPT-5.3 Codex Spark focuses on minimal, targeted changes—keeping the coding loop tight and efficient.
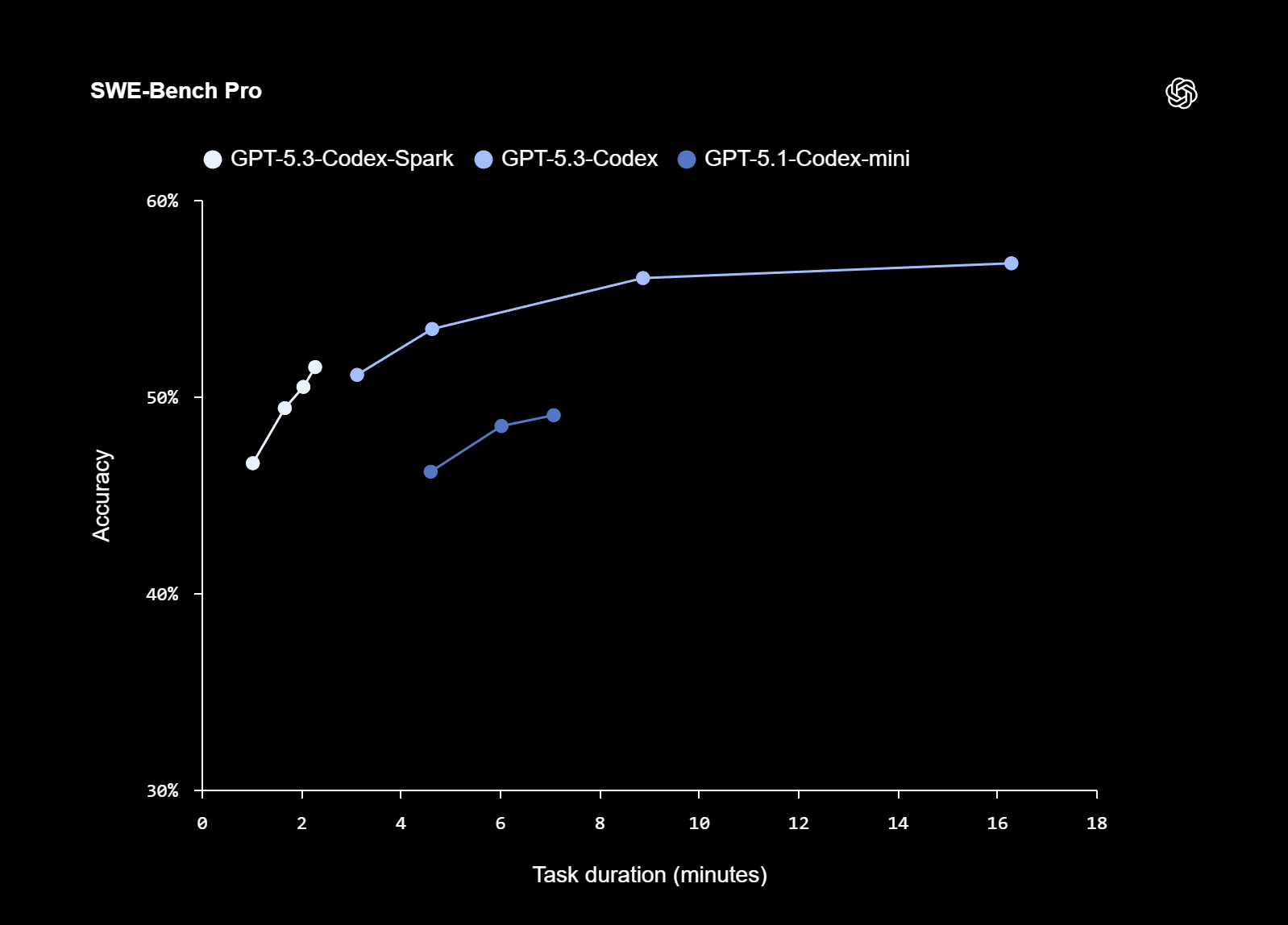
Performance: Fast Yet Capable
Despite being smaller than GPT-5.3-Codex, GPT-5.3 Codex Spark demonstrates strong performance on benchmarks like:
- SWE-Bench Pro
- Terminal-Bench 2.0
These benchmarks evaluate agentic software engineering capabilities. Spark delivers comparable competence while completing tasks in a fraction of the time, highlighting the performance-to-speed balance it achieves.
Engineering Latency Improvements Across the Stack
Speed isn’t just about the model—it’s about the entire pipeline.
To support GPT-5.3 Codex Spark, OpenAI implemented major end-to-end latency optimizations:
- 80% reduction in client/server roundtrip overhead
- 30% reduction in per-token overhead
- 50% reduction in time-to-first-token
Key upgrades include:
- Persistent WebSocket connections
- Streamlined response streaming
- Optimized inference stack
- Faster session initialization
The WebSocket serving path is enabled by default for Spark and is expected to become standard across other models.
These improvements benefit the entire ecosystem, not just GPT-5.3 Codex Spark.
Powered by Cerebras: Ultra-Low Latency Infrastructure
A key milestone behind GPT-5.3 Codex Spark is the partnership with Cerebras.
The model runs on the Cerebras Wafer Scale Engine 3, a purpose-built AI accelerator optimized for high-speed inference. This creates a latency-first serving tier that allows Codex to feel responsive in ways traditional GPU deployments may not achieve alone.
GPUs remain essential for cost-efficient large-scale training and inference. However, for workflows demanding ultra-fast response cycles, Cerebras hardware tightens the feedback loop significantly.
The result: a hybrid infrastructure where GPUs and Cerebras complement one another to deliver both scale and speed.
Availability and Research Preview Access
GPT-5.3 Codex Spark is currently available to:
- ChatGPT Pro users
- The latest Codex app
- Codex CLI
- VS Code extension
It is also being tested with select API design partners to explore integration possibilities in real-world products.
Because it runs on specialized low-latency hardware, access may be limited or queued during periods of high demand. Rate limits are governed separately during the research preview phase.
Safety and Deployment Standards
GPT-5.3 Codex Spark includes the same safety training as mainline models, including cyber-relevant safeguards.
It underwent standard deployment evaluations covering cybersecurity and biological risk capabilities and was determined not to reach high capability thresholds under OpenAI’s Preparedness Framework.
This ensures that while the model accelerates coding workflows, it remains aligned with responsible AI deployment practices.
Toward Dual-Mode Codex: Real-Time and Long-Horizon
GPT-5.3 Codex Spark represents the first step toward a Codex system with two complementary modes:
- Long-horizon reasoning and execution
- Real-time interactive collaboration
Future iterations aim to blend these modes seamlessly. Developers may soon be able to:
- Iterate interactively in tight loops
- Delegate longer-running subtasks to background agents
- Parallelize tasks across multiple models
- Combine breadth, speed, and autonomy
This shift signals a new era in developer-AI collaboration.
Why GPT-5.3 Codex Spark Matters
As AI models become more capable, interaction speed becomes the limiting factor.
Ultra-fast inference changes how developers think, experiment, and build. Instead of waiting for completion cycles, they can collaborate fluidly—turning ideas into working code at the speed of thought.
GPT-5.3 Codex Spark isn’t just a faster model. It redefines the rhythm of AI-assisted programming, narrowing the gap between intention and implementation.
And this is only the beginning of a new family of ultra-fast models designed to transform how software gets built.