ในโลกของปัญญาประดิษฐ์ที่เปลี่ยนแปลงอย่างรวดเร็ว การประมวลผลเสียงกลายเป็นองค์ประกอบสำคัญของแอปพลิเคชันยุคใหม่ ตั้งแต่การรู้จำเสียงพูดไปจนถึงการสร้างเสียง AI เครื่องมือเสียงที่ขับเคลื่อนด้วย AI กำลังนิยามใหม่ว่ามนุษย์โต้ตอบกับเทคโนโลยีอย่างไร และด้วยกระแสนี้ OpenAI จึงได้เปิดตัวโมเดลเสียงรุ่นถัดไปที่มาพร้อมความสามารถล้ำสมัยผ่าน API ของตน ในบทความนี้ เราจะสำรวจ OpenAI Audio Models ใหม่เหล่านี้ รวมถึงคุณสมบัติ ข้อดี และการใช้งานจริงในโลกธุรกิจ
การแนะนำ
ในช่วงไม่กี่เดือนที่ผ่านมา เราได้ลงทุนในการพัฒนาความฉลาด ความสามารถ และประโยชน์ของระบบตัวแทนที่ใช้ข้อความเป็นหลัก หรือที่เรียกว่าระบบที่สามารถดำเนินงานแทนผู้ใช้ได้อย่างอิสระ ด้วยการเปิดตัวเครื่องมือใหม่ ๆ อย่าง Operator, Deep Research, Computer-Using Agents และ Responses API ที่มาพร้อมเครื่องมือในตัว อย่างไรก็ตาม เพื่อให้ตัวแทนเหล่านี้มีประโยชน์อย่างแท้จริง ผู้คนจำเป็นต้องสามารถโต้ตอบกับระบบเหล่านี้ได้อย่างลึกซึ้งและเป็นธรรมชาติมากขึ้น ผ่านการสื่อสารด้วยภาษาพูดแทนที่จะใช้แค่ข้อความเพียงอย่างเดียว
วันนี้ เรากำลังเปิดตัวโมเดลเสียงใหม่สำหรับแปลงเสียงเป็นข้อความ (speech-to-text) และแปลงข้อความเป็นเสียง (text-to-speech) ผ่าน API ที่จะช่วยให้สามารถสร้างตัวแทนเสียงที่มีความสามารถ ปรับแต่งได้ และชาญฉลาดยิ่งขึ้น เพื่อสร้างคุณค่าที่แท้จริง โมเดล speech-to-text รุ่นล่าสุดของเราทำลายสถิติมาตรฐานเดิมด้วยความแม่นยำและความน่าเชื่อถือที่เหนือกว่า โดยเฉพาะในสถานการณ์ที่ท้าทาย เช่น สำเนียงที่หลากหลาย สภาพแวดล้อมที่มีเสียงรบกวน และความเร็วในการพูดที่แตกต่างกัน การปรับปรุงเหล่านี้ช่วยเพิ่มความแม่นยำของการถอดความ ทำให้เหมาะสมเป็นพิเศษสำหรับการใช้งานในศูนย์บริการลูกค้า การถอดบันทึกการประชุม และอื่น ๆ
เป็นครั้งแรกที่นักพัฒนาสามารถสั่งให้โมเดล text-to-speech พูดในลักษณะที่ต้องการได้ เช่น “พูดเหมือนพนักงานบริการลูกค้าที่เห็นอกเห็นใจ” ซึ่งเป็นการปลดล็อกระดับใหม่ของการปรับแต่งสำหรับตัวแทนเสียง ช่วยให้สามารถสร้างแอปพลิเคชันที่หลากหลาย ตั้งแต่เสียงบริการลูกค้าที่มีความเข้าอกเข้าใจและมีชีวิตชีวามากขึ้น ไปจนถึงการบรรยายที่มีอารมณ์และความสร้างสรรค์สำหรับประสบการณ์เล่าเรื่อง
เราเปิดตัวโมเดลเสียงรุ่นแรกในปี 2022 และตั้งแต่นั้นมา เราก็มุ่งมั่นที่จะพัฒนาความฉลาด ความแม่นยำ และความน่าเชื่อถือของโมเดลเหล่านี้อย่างต่อเนื่อง ด้วยโมเดลเสียงใหม่เหล่านี้ นักพัฒนาจะสามารถสร้างระบบแปลงเสียงเป็นข้อความที่แม่นยำและทนทานยิ่งขึ้น รวมถึงเสียงแปลงข้อความเป็นเสียงที่มีเอกลักษณ์และมีบุคลิก—all ผ่าน API เดียว
OpenAI Audio Models คืออะไร?
OpenAI Audio Models คือชุดเครื่องมือ AI ขั้นสูงที่ออกแบบมาเพื่อทำความเข้าใจ สร้าง และประมวลผลข้อมูลเสียง โมเดลเหล่านี้สร้างขึ้นบนสถาปัตยกรรม deep learning ที่มีความเชี่ยวชาญในงานต่าง ๆ เช่น การแปลงเสียงพูดเป็นข้อความ (STT), การแปลงข้อความเป็นเสียง (TTS), การจำลองเสียง, การจัดหมวดหมู่เสียง และการสร้างเสียง
การเปิดตัวล่าสุดของ OpenAI นำเสนอโมเดลเสียงรุ่นใหม่เข้าสู่ API ช่วยให้นักพัฒนาสามารถผสานรวมความสามารถด้านเสียงเข้ากับผลิตภัณฑ์ บริการ และแพลตฟอร์มได้อย่างไร้รอยต่อ โดยไม่จำเป็นต้องสร้างโมเดล AI ขึ้นมาเองตั้งแต่ต้น
คุณสมบัติเด่นของ OpenAI Audio Models รุ่นถัดไป
OpenAI ได้บรรจุฟีเจอร์ล้ำสมัยไว้ในโมเดลเสียงรุ่นถัดไปเหล่านี้ เพื่อรองรับแอปพลิเคชันที่เน้นการใช้งานด้านเสียงในหลายรูปแบบ
1. การรู้จำเสียงพูดที่แม่นยำสูง (STT)
โมเดลที่ได้รับการอัปเกรดสามารถถอดเสียงเป็นข้อความได้อย่างแม่นยำในระดับแนวหน้าของอุตสาหกรรม แม้ในสภาพแวดล้อมที่มีเสียงรบกวนหรือสำเนียงที่หลากหลาย เหมาะสำหรับการใช้งานเช่น ผู้ช่วยเสมือน การสนับสนุนลูกค้า และการถอดบันทึกการประชุม
2. การแปลงข้อความเป็นเสียงที่เป็นธรรมชาติ (TTS)
API รองรับฟังก์ชันการแปลงข้อความเป็นเสียงที่สมจริงมาก พร้อมตัวเลือกในการปรับแต่งสไตล์เสียง น้ำเสียง และอารมณ์ ช่วยให้สร้างเสียงพากย์สำหรับวิดีโอ หนังสือเสียง และระบบตอบรับอัตโนมัติ (IVR) ได้อย่างมีชีวิตชีวา
3. รองรับหลายภาษา
โมเดลเสียง OpenAI รองรับหลายภาษาและสำเนียง ทำให้เหมาะสำหรับการใช้งานระดับโลกในภูมิภาคและอุตสาหกรรมต่าง ๆ
4. การจำลองเสียงและการปรับแต่ง
โมเดลใหม่มาพร้อมความสามารถในการจำลองเสียง ช่วยให้นักพัฒนาสามารถสร้างเสียงเฉพาะตัวและเสียงที่เป็นเอกลักษณ์สำหรับผลิตภัณฑ์ ตัวละครเสมือน หรือเทคโนโลยีช่วยเหลือ
5. การประมวลผลเสียงแบบเรียลไทม์
ด้วยประสิทธิภาพที่มีความหน่วงต่ำ โมเดลเหล่านี้จึงได้รับการปรับแต่งสำหรับแอปพลิเคชันแบบเรียลไทม์ เช่น การสร้างคำบรรยายสด การประชุมเสมือน และอุปกรณ์ควบคุมด้วยเสียง
ข้อมูลเพิ่มเติมเกี่ยวกับโมเดลเสียงล่าสุดของเรา
โมเดลถอดเสียงพูดเป็นข้อความรุ่นใหม่
เราได้เปิดตัวโมเดลใหม่ gpt-4o-transcribe และ gpt-4o-mini-transcribe ที่มาพร้อมการปรับปรุงในด้านอัตราความผิดพลาดของคำ (Word Error Rate) และความสามารถในการรู้จำภาษาได้ดียิ่งขึ้นเมื่อเทียบกับโมเดล Whisper รุ่นดั้งเดิม
gpt-4o-transcribe แสดงให้เห็นถึงประสิทธิภาพ WER ที่ดีกว่าโมเดล Whisper รุ่นก่อนหน้าในหลากหลายเกณฑ์มาตรฐานที่ได้รับการยอมรับในวงกว้าง ซึ่งสะท้อนถึงความก้าวหน้าที่สำคัญของเราในเทคโนโลยีการถอดเสียงพูดเป็นข้อความ ความก้าวหน้าเหล่านี้เกิดจากนวัตกรรมที่พุ่งเป้าไปยัง reinforcement learning และการฝึกโมเดลในช่วงกลางที่เข้มข้นด้วยชุดข้อมูลเสียงที่หลากหลายและมีคุณภาพสูง
ด้วยเหตุนี้ โมเดลถอดเสียงพูดเป็นข้อความรุ่นใหม่เหล่านี้จึงสามารถจับความละเอียดอ่อนของการพูดได้ดีขึ้น ลดการเข้าใจผิด และเพิ่มความน่าเชื่อถือในการถอดความ โดยเฉพาะในสถานการณ์ที่ท้าทาย เช่น สำเนียงที่แตกต่างกัน สภาพแวดล้อมที่มีเสียงรบกวน หรือความเร็วในการพูดที่หลากหลาย โมเดลเหล่านี้พร้อมให้ใช้งานแล้วใน Speech-to-Text API (เปิดลิงก์ในหน้าต่างใหม่)
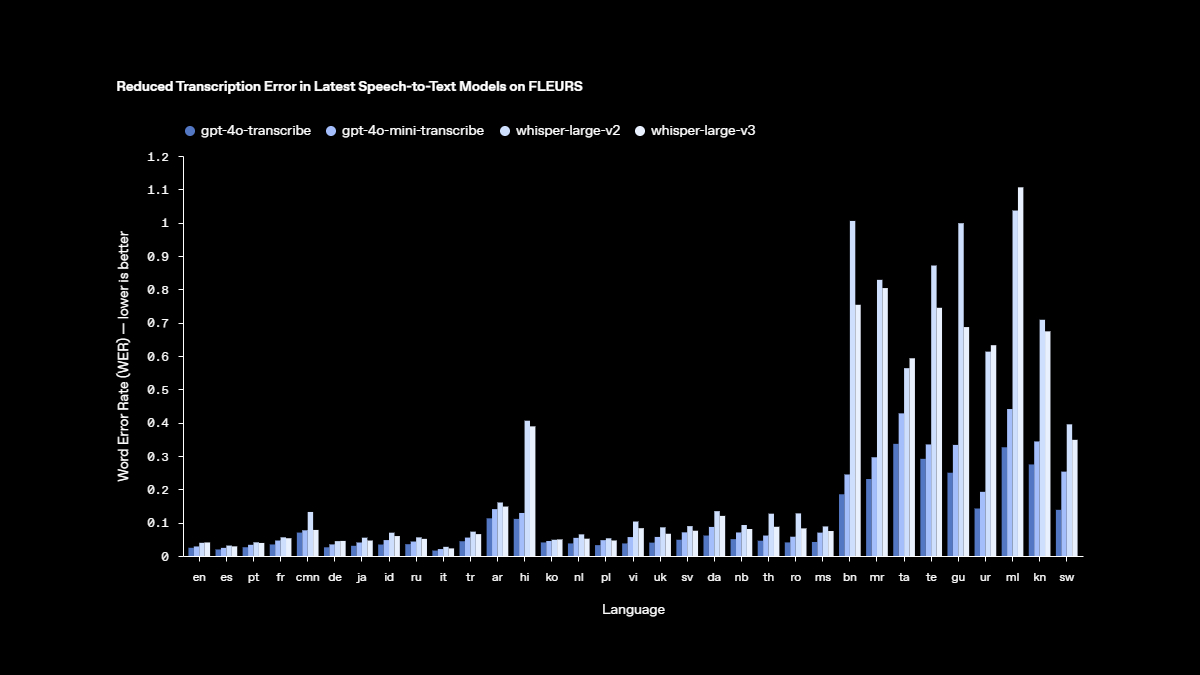
อัตราความผิดพลาดของคำ (Word Error Rate หรือ WER) คือมาตรวัดความแม่นยำของโมเดลรู้จำเสียงพูด โดยคำนวณจากเปอร์เซ็นต์ของคำที่ถอดผิดเมื่อเทียบกับข้อความอ้างอิง—WER ที่ต่ำกว่าจะดีกว่าและหมายถึงความผิดพลาดที่น้อยลง โมเดลถอดเสียงพูดเป็นข้อความรุ่นล่าสุดของเราทำได้ดีกว่าเดิมด้วยการลดค่า WER ลงในหลายเกณฑ์มาตรฐาน รวมถึง FLEURS (Few-shot Learning Evaluation of Universal Representations of Speech) ซึ่งเป็นชุดทดสอบเสียงพูดแบบหลายภาษาที่ครอบคลุมกว่า 100 ภาษา โดยใช้ตัวอย่างเสียงที่ได้รับการถอดความอย่างแม่นยำโดยมนุษย์
ผลลัพธ์เหล่านี้แสดงให้เห็นถึงความแม่นยำในการถอดความที่สูงขึ้นและการรองรับภาษาที่หลากหลายและแข็งแกร่งยิ่งขึ้น ดังที่แสดงไว้ในที่นี้ โมเดลของเราสามารถเอาชนะ Whisper v2 และ Whisper v3 ได้อย่างต่อเนื่องในทุกการประเมินภาษาที่ทำการทดสอบ
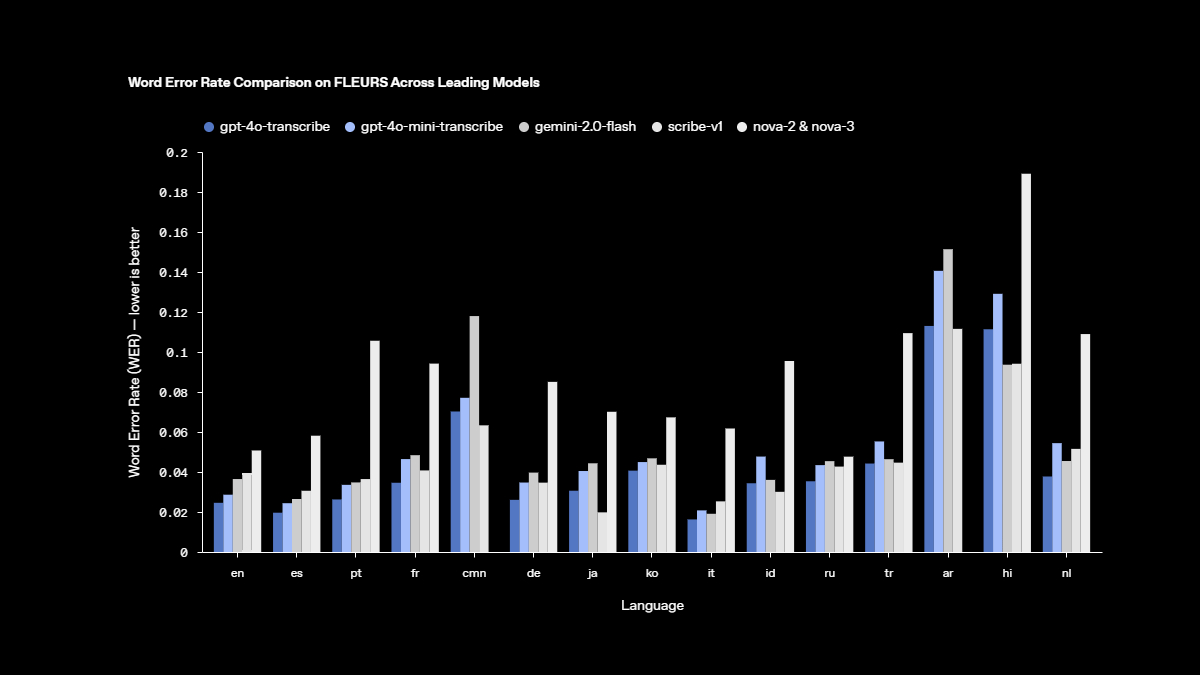
โมเดล text-to-speech รุ่นใหม่
เรายังเปิดตัวโมเดลใหม่ gpt-4o-mini-tts ซึ่งมีความสามารถในการควบคุมการออกเสียงได้ดีขึ้น โดยเป็นครั้งแรกที่นักพัฒนาสามารถ “กำหนดคำสั่ง” ให้โมเดลได้ไม่เพียงแค่ว่าจะพูดอะไร แต่รวมถึง “วิธีการพูด” ด้วย—เปิดโอกาสให้สามารถสร้างประสบการณ์แบบปรับแต่งได้มากขึ้น ตั้งแต่กรณีใช้งานด้านบริการลูกค้าไปจนถึงการเล่าเรื่องเชิงสร้างสรรค์ โมเดลนี้พร้อมใช้งานแล้วใน text-to-speech API (เปิดในหน้าต่างใหม่) ทั้งนี้ โมเดล text-to-speech เหล่านี้จำกัดการใช้งานไว้กับเสียงสังเคราะห์ที่ตั้งค่าไว้ล่วงหน้า ซึ่งเรามีการติดตามเพื่อให้แน่ใจว่าเสียงจะสอดคล้องกับรูปแบบเสียงสังเคราะห์ตามที่กำหนดไว้เสมอ
นวัตกรรมทางเทคนิคเบื้องหลังโมเดล
การ pretraining ด้วยชุดข้อมูลเสียงจริง
โมเดลเสียงรุ่นใหม่ของเราพัฒนาขึ้นบนสถาปัตยกรรม GPT‑4o และ GPT‑4o-mini โดยได้รับการ pretraining อย่างเข้มข้นด้วยชุดข้อมูลเฉพาะทางที่เน้นไปที่เสียง ซึ่งมีบทบาทสำคัญในการปรับประสิทธิภาพของโมเดล วิธีการที่มุ่งเน้นนี้ช่วยให้เข้าใจความละเอียดอ่อนของเสียงพูดได้ลึกซึ้งขึ้น และมอบประสิทธิภาพยอดเยี่ยมในงานที่เกี่ยวข้องกับเสียง
เทคนิคการ distillation ขั้นสูง
เราได้พัฒนาเทคนิคการ distillation ให้ก้าวหน้าไปอีกขั้น ช่วยให้สามารถถ่ายทอดองค์ความรู้จากโมเดลเสียงขนาดใหญ่ไปยังโมเดลขนาดเล็กที่มีประสิทธิภาพสูงกว่า ด้วยการนำวิธี self-play ขั้นสูงมาใช้ ชุดข้อมูล distillation ของเราสามารถเก็บรายละเอียดของบทสนทนาเสมือนจริงได้อย่างมีประสิทธิภาพ โดยจำลองการโต้ตอบระหว่างผู้ใช้งานกับผู้ช่วย AI ได้อย่างสมจริง สิ่งนี้ช่วยให้โมเดลขนาดเล็กสามารถสร้างคุณภาพของบทสนทนาและการตอบสนองที่ยอดเยี่ยมได้
แนวทาง reinforcement learning
สำหรับโมเดล speech-to-text เราได้ผสานแนวทาง reinforcement learning (RL) เข้าไปอย่างเต็มรูปแบบ เพื่อยกระดับความแม่นยำของการถอดความให้เป็นมาตรฐานใหม่ในอุตสาหกรรม วิธีการนี้ช่วยเพิ่มความแม่นยำและลดอัตราการแสดงผลข้อมูลผิดพลาด (hallucination) ได้อย่างมาก ทำให้โซลูชัน speech-to-text ของเรามีความสามารถในการแข่งขันสูงในสถานการณ์การรู้จำเสียงที่ซับซ้อน
ความก้าวหน้าเหล่านี้สะท้อนถึงความก้าวหน้าของวงการ audio modeling ที่ผสานนวัตกรรมเข้ากับการปรับปรุงที่ใช้งานได้จริง เพื่อเสริมประสิทธิภาพของแอปพลิเคชันเสียงให้ดียิ่งขึ้น
การใช้งานผ่าน API
โมเดลเสียงใหม่เหล่านี้พร้อมให้บริการแก่ทุกคนแล้ว – ดูข้อมูลเพิ่มเติมเกี่ยวกับการใช้งาน audio ได้ที่นี่ (เปิดในหน้าต่างใหม่) สำหรับนักพัฒนาที่กำลังสร้างประสบการณ์การสนทนาด้วยโมเดล text-based อยู่ การเพิ่มโมเดล speech-to-text และ text-to-speech ของเราเป็นวิธีที่ง่ายที่สุดในการสร้าง voice agent นอกจากนี้ เรายังเปิดตัวการเชื่อมต่อกับ Agents SDK (เปิดในหน้าต่างใหม่) ที่ช่วยลดความซับซ้อนในกระบวนการพัฒนา สำหรับนักพัฒนาที่ต้องการสร้างประสบการณ์ speech-to-speech ที่มีความหน่วงต่ำ แนะนำให้ใช้งานร่วมกับ speech-to-speech models ผ่าน Realtime API ของเรา
แผนในอนาคต
ในอนาคต เราวางแผนที่จะลงทุนเพิ่มเติมเพื่อพัฒนา AI ให้ฉลาดและแม่นยำยิ่งขึ้น รวมถึงสำรวจวิธีให้ผู้พัฒนาสามารถนำเสียงที่ปรับแต่งเองมาใช้ เพื่อสร้างประสบการณ์ที่เป็นส่วนตัวมากขึ้น โดยยังคงสอดคล้องกับมาตรฐานความปลอดภัยของเรา นอกจากนี้ เรายังคงร่วมมือกับผู้กำหนดนโยบาย นักวิจัย นักพัฒนา และนักสร้างสรรค์ เพื่อหารือเกี่ยวกับความท้าทายและโอกาสที่เสียงสังเคราะห์สามารถนำเสนอได้ เราตื่นเต้นที่จะได้เห็นนวัตกรรมและการใช้งานเชิงสร้างสรรค์ที่นักพัฒนาจะนำเสนอต่อไปโดยใช้ความสามารถด้านเสียงที่ได้รับการปรับปรุงนี้ ทั้งนี้ เรายังมีแผนลงทุนในสื่อรูปแบบอื่น ๆ เช่น วิดีโอ เพื่อช่วยให้นักพัฒนาสามารถสร้างประสบการณ์แบบมัลติโหมดที่ครบวงจรได้ในอนาคต
กรณีการใช้งาน OpenAI Audio Models
อุตสาหกรรม | Example of use |
Ecommerce | ผู้ช่วยช้อปปิ้งด้วยเสียงและระบบค้นหาสินค้าด้วยเสียง |
เฮลธ์แคร์ | เครื่องมือถอดความทางการแพทย์และระบบสรุปข้อมูลผู้ป่วยอัตโนมัติ |
สื่อและบันเทิง | พอดแคสต์ที่สร้างด้วย AI, หนังสือเสียง, และการพากย์เสียง |
Customer service | ระบบ IVR อัจฉริยะและบอทตอบกลับด้วยเสียง |
study | แพลตฟอร์ม e-learning แบบโต้ตอบพร้อมการบรรยายด้วย TTS |
วิธีเริ่มต้นใช้งาน OpenAI Audio Models
การเริ่มต้นใช้งานโมเดลเสียงเหล่านี้ง่ายมากสำหรับทั้งนักพัฒนาและธุรกิจ โดยสามารถดำเนินการได้ดังนี้:
- สมัครเพื่อขอรับ API key ผ่านแพลตฟอร์มอย่างเป็นทางการของ OpenAI
- เลือกใช้งาน audio endpoint ที่ต้องการ เช่น speech-to-text (STT) หรือ text-to-speech (TTS)
- ผสาน API เข้ากับแอปพลิเคชันของคุณผ่านภาษาการเขียนโปรแกรมยอดนิยม เช่น Python, JavaScript หรือ Go
- ปรับแต่งผลลัพธ์ได้ด้วยการตั้งค่าพารามิเตอร์ เช่น โทนเสียง, ภาษา, และค่าความหน่วง (latency) ตามความต้องการ
OpenAI ยังมีเอกสารและตัวอย่างโค้ดที่ครบถ้วนเพื่อช่วยให้การผสานระบบเป็นไปอย่างราบรื่น

Summary
การเปิดตัว OpenAI Audio Models ภายในระบบ API ถือเป็นก้าวสำคัญสำหรับนักพัฒนาและธุรกิจที่ต้องการนำพลังของ AI ด้านเสียงมาใช้ประโยชน์ ไม่ว่าจะเป็นแอปพลิเคชันเสียงแบบเรียลไทม์หรือการสร้างเนื้อหาอัตโนมัติ โมเดลเหล่านี้เปิดประตูสู่นวัตกรรมที่ไร้ขีดจำกัดในยุคการพัฒนาซอฟต์แวร์สมัยใหม่
ไม่ว่าคุณจะกำลังสร้างผู้ช่วยที่ขับเคลื่อนด้วย AI หรือพัฒนาเครื่องมือเพื่อเพิ่มความสามารถในการเข้าถึงของผู้ใช้งาน โมเดลเสียงรุ่นใหม่ของ OpenAI ก็พร้อมมอบประสิทธิภาพและความยืดหยุ่นที่คุณต้องการเพื่อก้าวนำในโลกเทคโนโลยีที่เปลี่ยนแปลงอย่างรวดเร็วในปัจจุบัน
คุณสามารถเรียนรู้เพิ่มเติมเกี่ยวกับเทคโนโลยีเสียงรุ่นล่าสุดได้ที่ เว็บไซต์ทางการของ OpenAI
Interested in Microsoft products and services? Send us a message here.
Explore our digital tools
If you are interested in implementing a knowledge management system in your organization, contact SeedKM for more information on enterprise knowledge management systems, or explore other products such as Jarviz for online timekeeping, OPTIMISTIC for workforce management. HRM-Payroll, Veracity for digital document signing, and CloudAccount for online accounting.
Read more articles about knowledge management systems and other management tools at Fusionsol Blog, IP Phone Blog, Chat Framework Blog, and OpenAI Blog.
Chatbot สำหรับ WebApp สร้างความผูกพันกับลูกค้าด้วยระบบอัตโนมัติ – Chatframework AI
Related Articles
- ChatGPT Canvas vs Gemini Canvas Comparison
- Taara Chip: The Next-Generation Innovation Reshaping Computing Power
- Email encryption with M365: A Comprehensive Guide to Encryption
- Copilot For Data Warehouse providing intelligent insights
- Analyze and manage big data with Copilot in Microsoft Fabric
- Microsoft Sentinel Pricing: The Complete Guide