ในโลกที่ขับเคลื่อนด้วยข้อมูล ธุรกิจจำเป็นต้องเลือกโซลูชันการจัดเก็บและวิเคราะห์ข้อมูลที่เหมาะสมเพื่อจัดการข้อมูลจำนวนมาก ทั้งข้อมูลที่มีโครงสร้างและไม่มีโครงสร้าง Data Warehouse vs Data Lake เป็นสองแนวทางหลักที่มีวัตถุประสงค์แตกต่างกันไปตามวิธีการจัดเก็บ ประมวลผล และวิเคราะห์ข้อมูล การทำความเข้าใจความแตกต่าง ประโยชน์ และกรณีการใช้งานของแต่ละแนวทางจะช่วยให้องค์กรสามารถปรับกลยุทธ์ข้อมูลให้เหมาะสมเพื่อการตัดสินใจและการดำเนินงานที่มีประสิทธิภาพยิ่งขึ้น
ทำความเข้าใจ Data Warehouse vs Data Lake
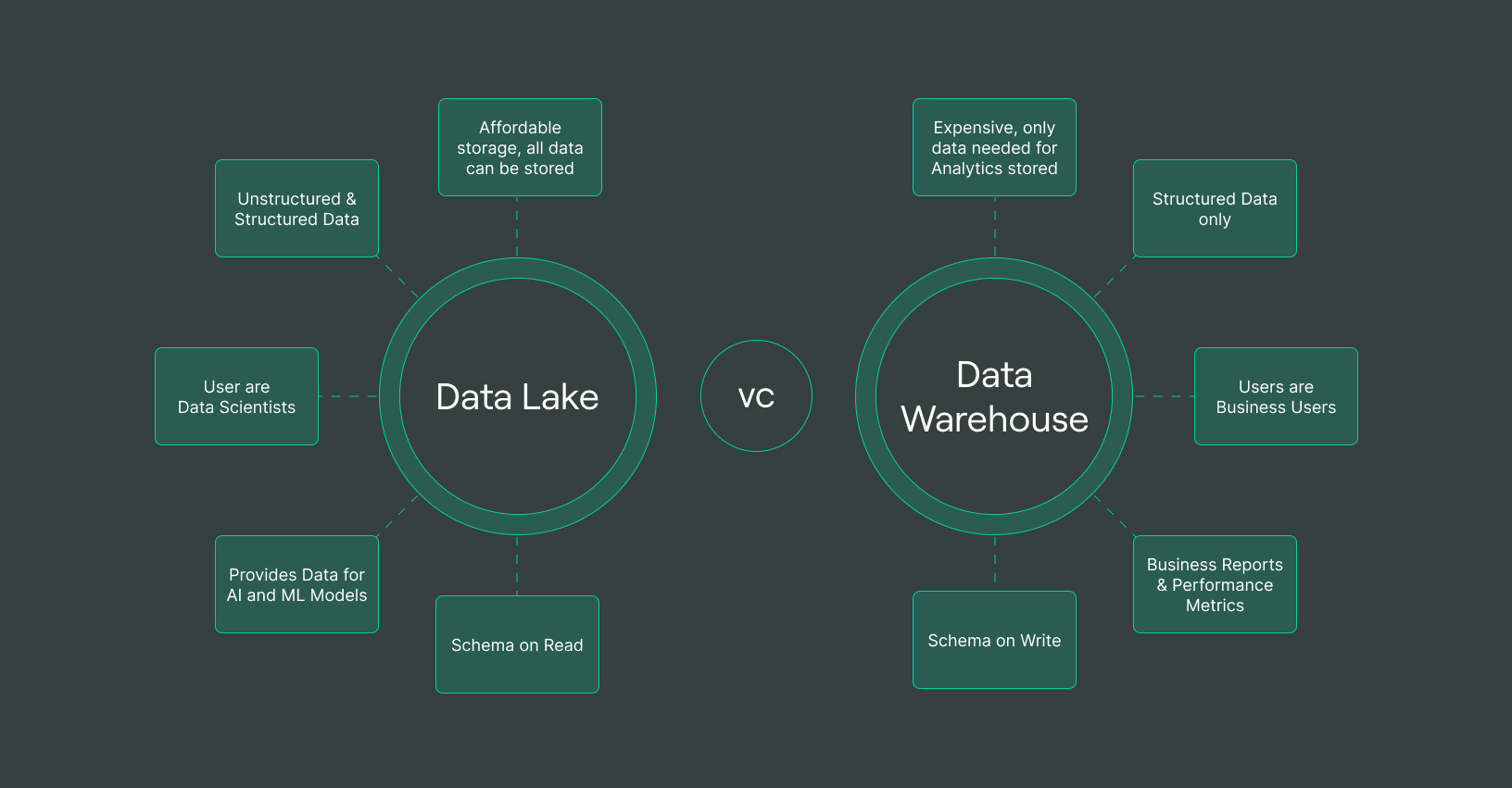
What is a Data Warehouse?
Data Warehouse เป็นศูนย์กลางจัดเก็บข้อมูลที่ออกแบบมาเพื่อเก็บข้อมูลที่มีโครงสร้างและผ่านการประมวลผลจากแหล่งต่างๆ ระบบนี้ได้รับการปรับให้เหมาะสำหรับ Business Intelligence (BI) การวิเคราะห์ และการรายงาน ซึ่งรับประกันความสม่ำเสมอของข้อมูลและประสิทธิภาพสูง ก่อนที่ข้อมูลจะเข้าสู่ Data Warehouse ข้อมูลต้องผ่านกระบวนการ Extract, Transform, Load (ETL) เพื่อให้แน่ใจว่ามีเฉพาะข้อมูลที่สะอาดและมีโครงสร้างเท่านั้นที่ถูกจัดเก็บ
คุณลักษณะสำคัญของ Data Warehouse:
- เก็บข้อมูลที่มีโครงสร้าง ผ่านการประมวลผล และเป็นระบบระเบียบ
- use schema-on-write หมายถึงข้อมูลถูกกำหนดโครงสร้างก่อนจัดเก็บ
- ปรับแต่งให้เหมาะสมสำหรับการรัน query ที่ซับซ้อน รายงาน และแดชบอร์ด
- Supported SQL-based queries เพื่อการดึงข้อมูลที่รวดเร็ว
- ให้ความแม่นยำและความสม่ำเสมอของข้อมูลสูง
กรณีการใช้งานทั่วไปของ Data Warehouse:
- Business Intelligence & Reporting – บริษัทใช้ Data Warehouse ในการสร้างรายงานการขาย วิเคราะห์ลูกค้า และติดตามการดำเนินงาน
- Financial analysis – ธนาคารและสถาบันการเงินใช้ Data Warehouse เพื่อเก็บข้อมูลธุรกรรมที่มีโครงสร้างเพื่อตรวจจับการทุจริตและบริหารความเสี่ยง
- การจัดการข้อมูลด้านสุขภาพ – โรงพยาบาลใช้ Data Warehouse ในการจัดเก็บประวัติผู้ป่วย ระบบเรียกเก็บเงิน และการปฏิบัติตามกฎระเบียบ
What is a Data Lake?
Data Lake เป็นระบบจัดเก็บข้อมูลที่มีความยืดหยุ่นสูง สามารถรองรับ ข้อมูลดิบที่ยังไม่ผ่านการประมวลผล ได้ในขนาดใหญ่ ต่างจาก Data Warehouse ตรงที่ Data Lake สามารถจัดเก็บ ข้อมูลที่มีโครงสร้าง กึ่งโครงสร้าง และไม่มีโครงสร้าง ได้ในรูปแบบดั้งเดิมของข้อมูล โดยไม่ต้องกำหนดโครงสร้างล่วงหน้า ทำให้มีความยืดหยุ่นมากขึ้นสำหรับการประมวลผลข้อมูลขนาดใหญ่ ปัญญาประดิษฐ์ (AI) และแมชชีนเลิร์นนิง (ML)
คุณลักษณะสำคัญของ Data Lake:
- รองรับการจัดเก็บข้อมูลดิบ ข้อมูลกึ่งโครงสร้าง และข้อมูลไม่มีโครงสร้าง
- use schema-on-read หมายถึงกำหนดโครงสร้างข้อมูลเมื่อมีการใช้งาน
- รองรับหลากหลายรูปแบบข้อมูล เช่น ข้อความ รูปภาพ วิดีโอ และข้อมูลจากเซ็นเซอร์ IoT
- Suitable for Big Data Analytics, AI และ Machine Learning
- มีต้นทุนต่ำกว่าการใช้ Data Warehouse แบบดั้งเดิม
กรณีการใช้งานทั่วไปของ Data Lake:
- Big Data Analytics – ธุรกิจค้าปลีกใช้ Data Lake ในการวิเคราะห์พฤติกรรมลูกค้าและคาดการณ์แนวโน้มการซื้อ
- ปัญญาประดิษฐ์และแมชชีนเลิร์นนิง – Data Lake เป็นที่เก็บข้อมูลขนาดใหญ่สำหรับฝึกโมเดล AI
- IoT และการประมวลผลแบบเรียลไทม์ – อุปกรณ์อัจฉริยะสามารถส่งข้อมูลเซ็นเซอร์ไปยัง Data Lake เพื่อการคาดการณ์บำรุงรักษาและการทำงานอัตโนมัติ
Data Warehouse vs Data Lake: ความแตกต่างหลัก
Feature | Data Warehouse | Data Lake |
Data type | ข้อมูลที่มีโครงสร้างเท่านั้น | ข้อมูลที่มีโครงสร้าง กึ่งโครงสร้าง และไม่มีโครงสร้าง |
Processing | ข้อมูลต้องผ่านการประมวลผลก่อนจัดเก็บ (ETL) | ข้อมูลถูกจัดเก็บก่อนและประมวลผลเมื่อต้องการใช้ (ELT) |
ประสิทธิภาพการสืบค้น | ปรับแต่งให้เหมาะกับการสืบค้นข้อมูลเชิงวิเคราะห์ที่รวดเร็ว | ต้องการการประมวลผลเพิ่มเติมสำหรับการสืบค้นข้อมูลที่มีโครงสร้าง |
ต้นทุนการจัดเก็บ | สูงกว่า เนื่องจากมีโครงสร้างที่ปรับแต่งมาโดยเฉพาะ | ต่ำกว่า เนื่องจากเก็บข้อมูลดิบโดยไม่ต้องแปลงก่อน |
expandability | มีข้อจำกัดในการขยายตัว | ขยายตัวได้สูง รองรับข้อมูลขนาดใหญ่ได้ดี |
Use cases | BI, รายงานทางธุรกิจ, การวิเคราะห์ทางการเงิน | Big Data, AI, IoT, การวิเคราะห์เชิงพยากรณ์ |
การเลือกโซลูชันที่เหมาะสม
ควรใช้ Data Warehouse เมื่อ:
- องค์กรต้องการข้อมูลที่มีโครงสร้างและคุณภาพสูงสำหรับ Business Intelligence (BI) และการรายงาน
- ต้องการรัน query แบบ SQL เพื่อการวิเคราะห์และตัดสินใจที่รวดเร็ว
- ข้อมูลมาจากหลายแหล่งและต้องผ่านกระบวนการทำความสะอาดและแปลงก่อนนำไปวิเคราะห์
- การปฏิบัติตามข้อกำหนดและการกำกับดูแลข้อมูลเป็นสิ่งสำคัญ โดยต้องมี data integrity และ security ที่เข้มงวด
ควรใช้ Data Lake เมื่อ:
- ธุรกิจต้องจัดการ ข้อมูลจำนวนมากที่ไม่มีโครงสร้างหรือกึ่งโครงสร้าง
- ต้องการโซลูชันการจัดเก็บที่ยืดหยุ่นสำหรับ Big Data, AI หรือ Machine Learning
- ข้อมูลเติบโตอย่างรวดเร็ว และต้องการ โซลูชันที่สามารถขยายขนาดได้ง่าย
- ต้องการ ลดต้นทุน ในการจัดเก็บข้อมูล โดยเก็บข้อมูลดิบไว้และประมวลผลเมื่อต้องการใช้งาน
แนวทางแบบไฮบริด: Data Lakehouse – ผสานจุดแข็งของทั้งสองแนวทาง
หลายองค์กรเริ่มนำแนวทาง Lakehouse Architecture มาใช้ ซึ่งเป็นการรวมข้อดีของ Data Warehouse vs Data Lake เข้าด้วยกัน Data Lakehouse มีคุณสมบัติดังนี้:
- จัดเก็บทั้งข้อมูลที่มีโครงสร้างและไม่มีโครงสร้าง ในสภาพแวดล้อมเดียวกัน
- use schema-on-read เพื่อการวิเคราะห์ที่ยืดหยุ่น ในขณะที่ยังคงมาตรฐานด้านความปลอดภัยและการกำกับดูแล
- Supported SQL-based queries พร้อมทั้งรองรับงาน AI และ Machine Learning
- customize ต้นทุน ได้โดยการแยกโครงสร้าง Storage และ Compute ออกจากกัน
ตัวอย่างกรณีใช้งานของ Data Lakehouse:
- E-Commerce & Retail - use Lakehouse ในการรวมข้อมูลยอดขายที่มีโครงสร้าง (Data Warehouse) เข้ากับข้อมูลพฤติกรรมลูกค้า (Data Lake)
- Healthcare & Genomics - use Lakehouse ในการจัดเก็บ ประวัติผู้ป่วยที่มีโครงสร้าง ในขณะที่ยังสามารถใช้ Machine Learning วิเคราะห์ข้อมูลจีโนมที่ไม่มีโครงสร้าง
- Manufacturing & IoT – ผสาน รายงานปฏิบัติการที่มีโครงสร้าง เข้ากับ ข้อมูลเซ็นเซอร์ IoT ที่ไม่มีโครงสร้าง เพื่อการคาดการณ์ซ่อมบำรุง
Summary
การเลือกใช้โซลูชันจัดเก็บข้อมูลขึ้นอยู่กับเป้าหมายทางธุรกิจ กลยุทธ์ข้อมูล และวัตถุประสงค์ในการวิเคราะห์
- Data Warehouse เหมาะสำหรับข้อมูลที่มีโครงสร้าง รองรับ Business Intelligence (BI) และต้องการ ข้อมูลที่พร้อมใช้งาน
- Data Lake เป็นโซลูชันที่มีความยืดหยุ่นสูง รองรับ Big Data, AI และ Machine Learning
สำหรับหลายองค์กร แนวทางแบบ Lakehouse เป็นตัวเลือกที่ดีที่สุด เนื่องจากให้ความสมดุลระหว่าง ความสามารถในการขยายขนาด ต้นทุนที่เหมาะสม และประสิทธิภาพการวิเคราะห์ข้อมูล การเข้าใจความแตกต่างเหล่านี้ช่วยให้ธุรกิจสามารถ ตัดสินใจอย่างชาญฉลาด และสร้าง โครงสร้างพื้นฐานด้านข้อมูล ที่แข็งแกร่งสำหรับความสำเร็จในระยะยาว
หากต้องการเรียนรู้เพิ่มเติมเกี่ยวกับแนวทางการจัดเก็บและวิเคราะห์ข้อมูลที่มีประสิทธิภาพ สามารถดูรายละเอียดเพิ่มเติมได้ที่ แหล่งข้อมูลนี้
Explore our digital tools
If you are interested in implementing a knowledge management system in your organization, contact SeedKM for more information on enterprise knowledge management systems, or explore other products such as Jarviz for online timekeeping, OPTIMISTIC for workforce management. HRM-Payroll, Veracity for digital document signing, and CloudAccount for online accounting.
Read more articles about knowledge management systems and other management tools at Fusionsol Blog, IP Phone Blog, Chat Framework Blog, and OpenAI Blog.